机器学习与算法交易
机器学习在算法交易中的发展潮流
量化投资与因子制取方法的发展
随着交易不断的高频化和隐藏化,为了在混乱的交易中脱颖而出,则需要研究更加优秀的算法;同时,由于交易和风险紧密相连,风险因子的探究也变得愈发重要,从单因子逐渐演变为了双因子。
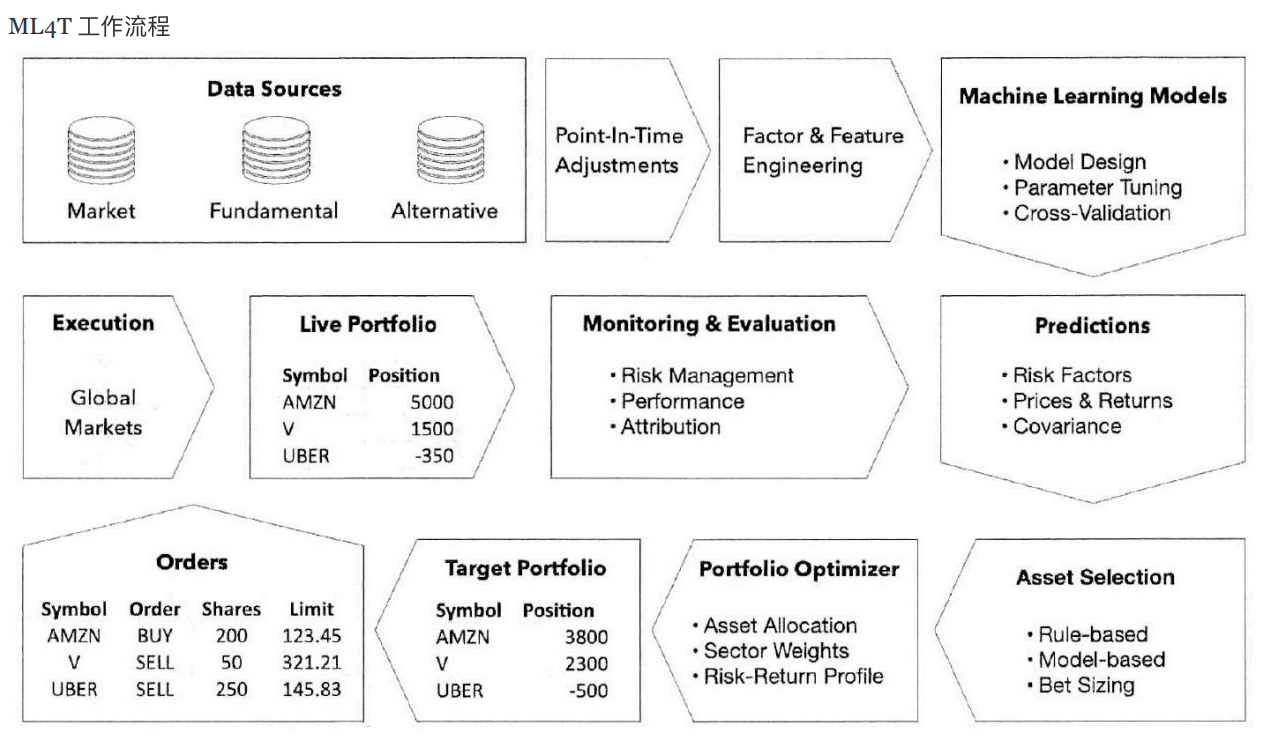
在重视程度方面,基本面投资者也开始愈加关注量化投资方法。在数据选择上,因为内幕数据的不合法隐患,用算法高效处理各类大量数据显得愈加重要,尤其是另类数据获得了越来越广泛的关注。利用机器学习驱动交易的策略可用下图的方式呈现:
阿尔法因子的研究流程则如下图所示:

- 研究阶段
- ⼀个预测性因⼦能够捕捉数据源与重要策略输⼊(如资产回报)之间系统性关系的某个⽅⾯。优化预测能⼒需要创造性的特征⼯程,即有效的数据转换。
- 数据挖掘导致的错误发现是⼀个需要谨慎管理的关键⻛险,许多投资者仍然偏爱那些与⾦融市场和投资者⾏为理论相符的因⼦。
- 验证阿尔法因⼦的信号内容,需要在⼀个有代表性的背景下对其预测能⼒进⾏稳健的评估。
- 执⾏阶段
- 执⾏阶段,阿尔法因⼦发出信号,从⽽产⽣买⼊或卖出订单。
- 由此产⽣的投资组合头⼨,⼜具有特定的⻛险状况,这些⻛险状况相互作⽤,共同构成了投资组合的总体⻛险。
- 策略回测
- 涉及⼴泛的实证检验,其⽬标是根据该理念在不同样本外市场情景中的表现来决定是否将其摒弃。
- 检验过程可能涉及使⽤模拟数据,以捕捉那些被认为可能发⽣但未在历史数据中反映的情景。
- 为获得候选策略的⽆偏绩效评估,需要⼀个能真实模拟其执⾏过程的回测引擎。
- 除数据或统计⽅法使⽤不当可能引⼊的潜在偏差外,回测引擎还需要根据市场状况,准确地呈现交易信号评估、下单和执⾏等实际操作环节。
三轮量化策略演进
- 第一波:学术信号时代(1980s–1990s)
- 量化策略主要来自学术研究成果,依赖极少数输入(如市盈率、价格估值等),使用传统市场与基本面数据进行交易。
- AQR 创立于 1998 年,主要使命是将这些信号规模化实现。这些策略后来基本商品化,并以 ETF 或简单均值回归策略呈现。
- 第二波:因子投资和智能贝塔时代(2000s)
- 基于 Eugene Fama 和 Kenneth French 的研究,多因子模型(如价值、规模、动量)开始流行,基金设计依据这些因子做套利或组合倾斜。
- 2007 年 8 月,因金融危机导致赎回潮,引发“量化地震”,波及整个因子基金行业。
- 这类策略以 long-only smart beta 形式广泛存在,组合倾斜于特定风险因子。
- 第三波:机器学习与另类数据时代(2010s 至今)
- 近年来大量投入于 ML 能力与另类数据(如卫星图像、社交媒体、文本数据等)以生成盈利信号。
- 面临“因子衰减”挑战:研究显示,一个新发现的异常信号从发现到发表通常收益下降 25%,发表后因竞争和拥挤带来的超额回报可能下降超过 50%。
当代交易者与机构更倾向于使用算法执行一系列不同目标,包括:
- 智能执行算法:如时间加权或成交量加权平均出价,降低市场影响和滑点;
- 高频交易(HFT)策略:超短持仓,捕捉微小价差和统计套利;
- 行为策略:预测大玩家行为、系统嗅探;
- 价格和回报预测策略:基于绝对和相对价格、回报趋势预测进行交易。
这些策略大多聚焦于短期至中期相对价格变化,非常适合结合机器学习进行预测和执行优化。
测试交易构想
回测是筛选成功算法交易策略的关键⼀步。当与适当的多重测试校正⽅法相结合时,使⽤合成数据进⾏交叉验证是⼀项关键的机器学习技术,可以⽣成可靠的样本外结果。⾦融数据的时间序列性质要求对标准⽅法进⾏修改,以避免前视偏差或以其他⽅式污染⽤于训练、验证和测试的数据。此外,历史数据的有限性也催⽣了使⽤合成数据的替代⽅法。
市场和基本面数据源与技术
在交易过程中,数据一直是重要驱力,针对数据压缩获取时间和建立私有数据集提取信号都是常见手法;需要深入了解的内容包括,市场数据和基本面数据的来源、它们反映其产生环境的方式等。
-
市场数据
市场数据反映其环境,内容包含整个交易过程中的各种操作和数据,反映了交易场所的制度环境(包括管理订单、交易执行和价格形成的规则法规);这些数据常被用于分析订单流等交易数据,从而提取交易信号,进而捕捉到对供需动态或市场参与者行为的洞察
高频市场数据可被分为两大类别:
- 综合数据源(Consolidated Feed):汇总所有交易场所的交易与报价数据,由SIP统一发布;提供全国最佳买卖报价(NBBO)和最近成交信息,但仅包括“最好报价”,未展示全部订单深度
- 交易所专有数据源(Exchange Proprietary Feed):每家交易所提供自己的 tick 级(逐笔)订单流数据,包括所有订单、交易及其价格变动;提供完整订单簿、深度报价,以及市场参与者的行为信息,更适合对延迟敏感、需要完整流动性视图的高频交易者。
数据类型 来源 时间分辨率 内容深度 使用场景 Tick-by-Tick(Tick) 交易所专有 Feed 毫秒/纳秒级别 完整订单+报价流 高频交易、市场微结构研究 Level 1 / 2 / 3 综合或专有 Feed Tick 事件 深度逐级报价、订单行为 策略构建、Liquidity 分析 分钟 K 线(Minute Bar) AlgoSeek 等综合 Feed 固定时间间隔(如 1 分钟) OHLC + 高级特征 因子研究、机器学习模型训练 -
市场微观结构
市场微观结构研究制度环境如何影响交易过程,并塑造价格发现、买卖价差和报价、⽇内交易⾏为以及交易成本等结果;通过追踪快速演变且复杂的细节,以确保以最优市场价格执⾏交易,并设计利⽤市场摩擦的策略。
-
交易类型
交易者可以下达各种类型的买⼊或卖出订单,订单执行条件各不相同但一般在同一交易日内有效。
-
交易地点
-
交易所:包括集中式交易所(Exchange),其高度组织化,透明化交易,按最优价格时间成交;也包括场外交易市场(OTC),监管要求较低,适用于更多证券,流动性较低、灵活性更高。
-
订单撮合机制:包括集中订单簿+做市商(NYSE模式),由唯一做市商管理订单并撮合交易,其能提供最佳买卖价并维护市场秩序;也包括多做事商竞争(Nasdaq模式),该种方案使得市场信息碎片化,使公允价格判定难度加大。
-
暗池:交易前不公开订单价格、数量及参与者,仅在成交后延迟报告(通常向 FINRA 报告),适合大宗交易,能减少市场冲击、滑点,但缺乏交易透明度、存在被操纵风险
-
订单数据解析——以ITCH v5.0为例
原始数据获取与逐笔数据生成
TCH(TotalView‑ITCH) 是纳斯达克提供的二进制市场数据协议,用于传递逐笔订单流,支持市场参与者完整重建订单簿。它定义了 超过 20 种消息类型,包括系统事件、股票目录(symbol)、限价单的新增/修改/删除、交易执行、交叉盘信息(cross trades)以及集合竞价(NOII)等重要数据项目。
主要消息类型及其业务含义包括:
-
价订单生命周期相关
- A(Add Order 无归属)/F(Add Order 带 MPID 归属):表示在订单簿中添加一个新的限价买卖订单。F 型消息额外包含该订单的市场参与者身份(MPID)
- U(Order Replace):表示对现有订单重新下单,生成新的订单参考号,并更新价格与数量(旧订单移除)
- X(Order Cancel):表示部分取消订单,减少其显示数量,但订单仍存在
- D(Order Delete):表示完全取消订单,将其从订单簿彻底移除
-
执行相关(交易类型)
- E(Order Executed):表示限价单已全部或部分执行,成交数量会累积;通常跟踪 display orders
- C(Order Executed With Price):表示以与显示价格不同的价格成交,常用于“价格改善”情形。此消息包含成交价格和是否可见(printable 标识)
- P(Trade Message,Non‑Cross):用于非公开显示订单(如暗池订单)的成交事件,不影响订单簿结构,但用于成交统计和量化数据计算
-
交叉盘与集合竞价
- Q(Cross Trade Message):表示开盘、收盘或其他交叉拍卖的成交结果,是一笔大宗集合交易。提供交叉成交数量、价格和类型(O: Opening, C: Closing, I: Intraday, H: Halted)
- I(NOII:Net Order Imbalance Indicator):在交叉竞价前提供价格参考与买卖不平衡信息,帮助参与者判断开盘/收盘价格趋势
概念补充
- 限价单(Limit Order):设定价格与数量挂单,等待成交或被取消
- 归属与无归属订单:F 消息显示 MPID,而 A 消息则不指明参与者
- 交叉盘(Cross Trade):在指定时段(如开盘、收盘)以集合竞价方式执行交易,大宗订单集中成交
- 非公开成交(Non‑displayable Order Execution):通过 P 类型消息报告,不影响公开订单簿
- 价格改善(Price Improvement):成交价格优于订单初始显示价,通过 C 消息体现
- NOII:集合竞价前的净不平衡指标,为开盘/收盘价格提供参考
- Broken Trade(B):当成交被判定失效后通知,更正历史记录
基于逐笔数据的处理与可视化
基本内容
研究场景:高频与日内量化策略、大宗交易分析、微观结构研究等,需要对“逐笔(tick-by-tick)”市场数据做后续建模或回测。 规整需求:
- 降低纳秒级噪音波动带来的干扰;
- 构建稳定、可比较的固定节奏(或固定“成交量/价值”节奏)序列;
- 提取直观且有统计意义的特征(OHLCV、VWAP、买卖差、成交分布等)。
因为原始逐笔数据具有的时间索引不规则、价格振荡噪声、数据体量巨大等特性,需要构建更加清晰的时间序列:
- 读入原始 Tick
- 过滤市场时段(剔除集合竞价、盘前盘后或交叉盘消息,如需可保留交叉盘做专门分析)
- 分组聚合
- 按时间、成交量或成交额分箱
- 计算区间 OHLCV、VWAP、成交笔数、买卖价差、交叉盘量等
- 输出 Bars 序列
- 可视化与检验
- 分位估计、分布正态性检验(e.g. Normaltest)
- 价量关系、流动性深度对比
常用市场数据 API 访问方式
| 工具 | 数据类型 | 特点 |
|---|---|---|
| pandas-datareader | 日终/周/月线 OHLCV | 多来源、内置接口(Tiingo、IEX、Fama/French…) |
| yfinance | 日内/日终 OHLCV、公司行为 | 免费、极简 API、仅最近几天秒级数据 |
| Quantopian | 分钟线、基本面、另类数据 | Jupyter 策略回测平台、众包、实时模拟 |
| Zipline | 回测引擎 | 离线/线上一致的算法研发框架 |
| Quandl | 多资产类别历史数据 | 免费/付费、批量下载、灵活查询 |
基本面数据、报表数据
在算法交易中,基本⾯数据以及基于这些数据构建的特征可以直接⽤于⽣ 成交易信号(例如,作为价值指标),同时也是包括机器学习模型在内的预测模型的重要输⼊。财务报表数据则是基本⾯分析的主要数据来源,因为这些证券的价值取决于发⾏⼈的业务前景和财务健康状况。
构建基本面数据时间序列
目的:将公司财报中数值与脚注信息,按季度或年度整理为可用于量化分析与回测的时间序列
应用场景:
- 估值因子(如市盈率 P/E、净资产收益率 ROE)
- 跨期基本面指标趋势分析
- 因子研究中的信号对齐(将财报与市场数据同步)
综合来看,市场数据和基本面数据构成了大多数交易策略的支柱。