讨论:从《DeepSeek-R1 通过强化学习激励LLM中的推理》开始
讨论:从《DeepSeek-R1 通过强化学习激励LLM中的推理》开始
关键观点:LLM 的推理能力可以通过纯强化学习 (RL) 来激励,从而无需人工标记的推理轨迹
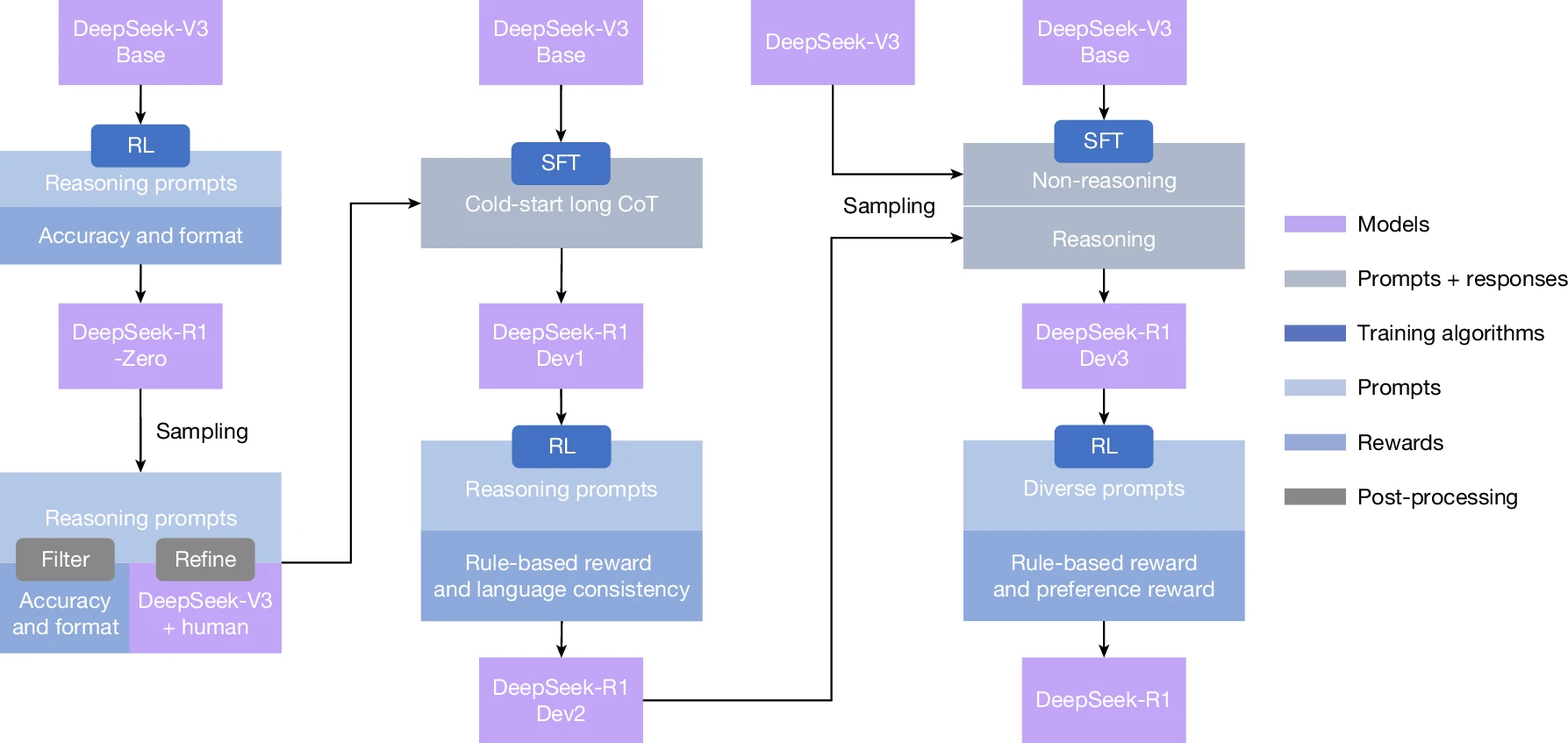
讨论点一:推理
如何训练LLM的推理能力
如何在给予LLM自主推理的同时优化沟通体验
强化学习
GRPO与PPO
奖励机制设置
提出两种奖励:基于规则的奖励(准确率奖励+格式奖励)和基于模型的奖励(是否有用+是否安全)
本文由作者按照 CC BY 4.0 进行授权