赞哦校园集市分析助手
总览
2024年暑假,本人计划开始构建一个能智能提取、分类的校园集市助手,可惜当时技术和时间有限,在随便完成爬取后就匆匆作罢;2025年暑假,因为多了一年的历练和实习等原因,技术力具有一定提升,因此决定重拾去年未竟之事,做一个初步完整的项目构建,完成了除前端页面外的其它内容。完整项目的构建思路如下:
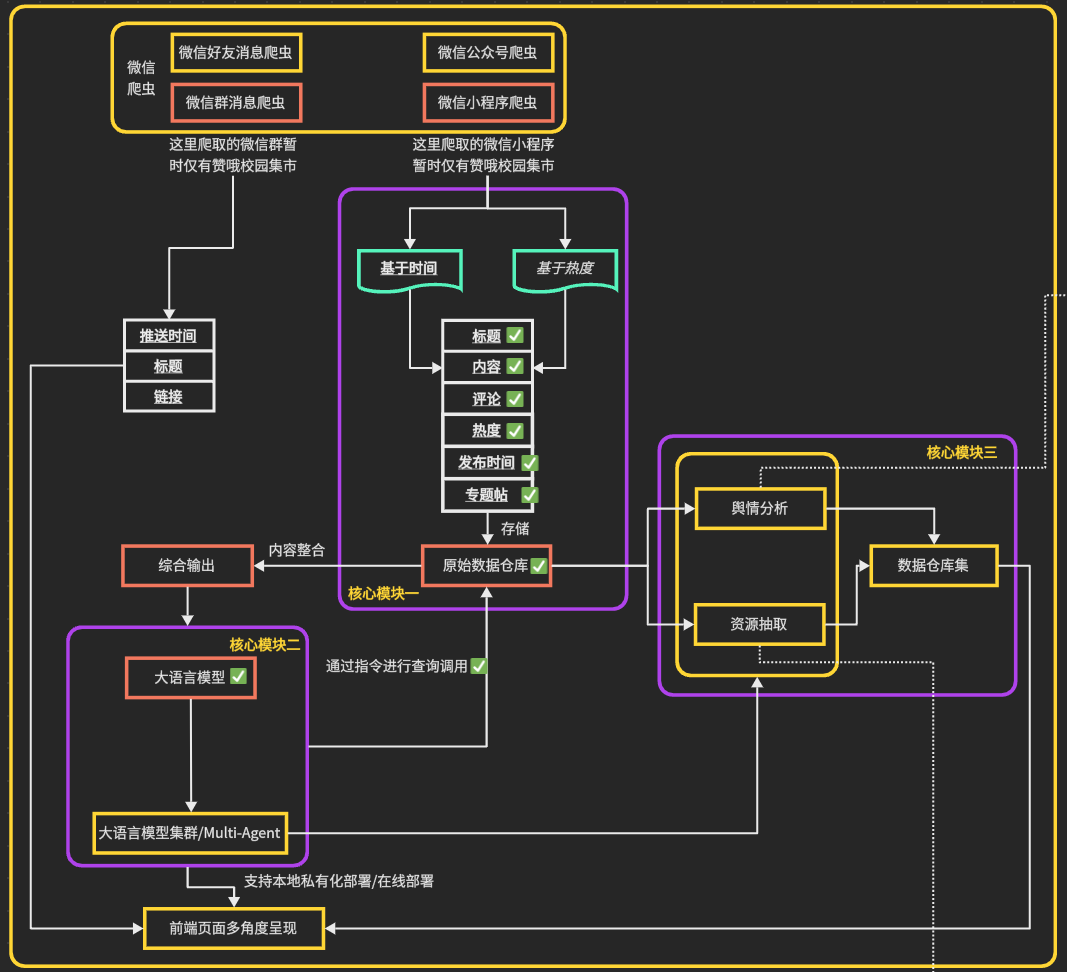
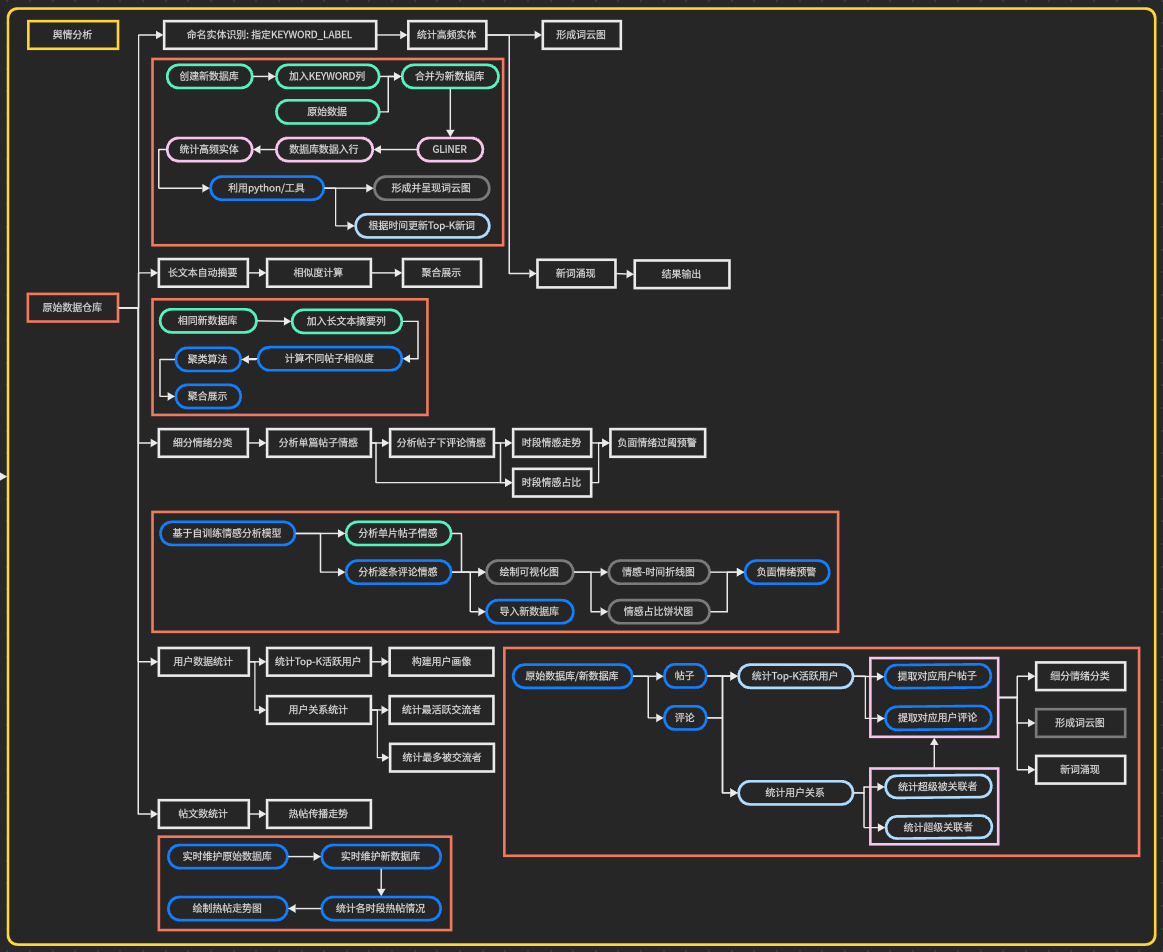
舆情分析的具体构建思路如下:
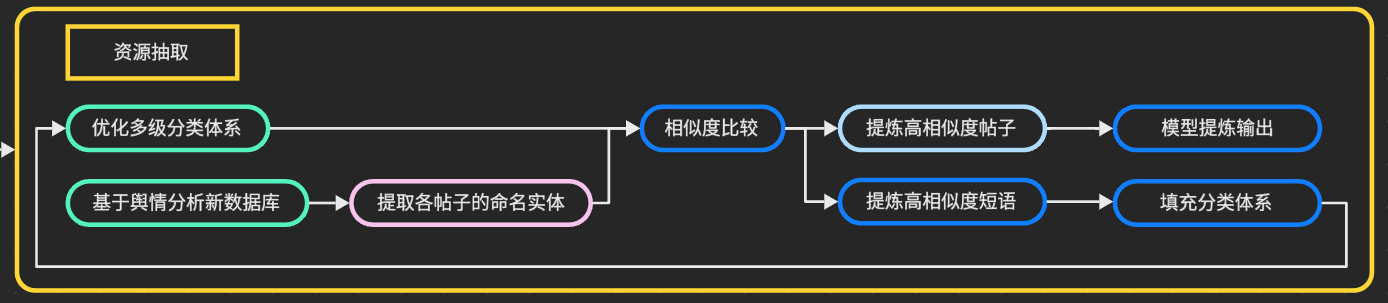
资源抽取的具体构建思路如下:
软件和环境准备
整体概括
上述整个过程基于Python,通过在Docker容器中创建隔离环境、在Dify上构建LLM工作流实现;数据存储使用数据库,利用轻量化的DB Broswer(SQLite)查看;微信群爬虫部分使用wxdump实现;逆向部分使用Github上的pc_wxapkg_decrypt解码,使用wxappUnpacker和wxapkg进行小程序逆向和比对;API请求部分使用Flask API,适配OpenAPI的Schema协议,实现本地和Dify平台工具的关联;模型部分通过ollama拉取和huggingface接口的方式进行使用,包括主模型gemma3、文本嵌入模型granite-embedding:278m、情感分析模型Erlangshen-Roberta-330M-Sentiment、Zero-shot命名实体识别模型gliner-x-large、中文转向量模型text2vec-base-chinese。
编程环境
具体的Conda环境见附录
Docker环境
Docker环境主要有两个,一个是集市爬虫运行需要的环境,一个是Dify运行需要的环境。这将在后面展开更进一步的说明。
其它要求
你需要有账号登录并进入到Docker、Huggingface、Github、微信
项目构建过程
微信群爬虫
该部分的代码结构为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- data
|- original_data
|- [提取到的txt/csv文件]
|- polished_data
|- [整理后的csv文件]
- wx_login //检测和模拟登入微信
|- core_utils
|- __init__.py
|- _loger.py
|- memory_search.py
|- common_utils.py
|- main.py //用于运行wx_login和group_chat_getter两部分的主文件
|- wx_info_handler.py
|- WX_OFFS.json
- group_chat_getter //微信群消息获取
|- decryption_module
|- utils
|- __init__.py
|- _loger.py
|- memory_search.py
|- ctypes_utils.py
|- common_utils.py
|- decryption.py
|- exporter.py
|- interactive_cli.py
- format_polisher
|- integrated_cleaner.py //用于清洗群爬虫模块得到的结果
主函数解释
该部分作为一个微信聊天记录导出工具存在。它负责协调 wx_login 和 group_chat_getter 两个核心模块,通过读取正在运行的微信客户端内存,获取关键信息(特别是数据库密钥),然后使用该密钥解密本地的微信数据库文件,最后从中提取指定群聊在特定时间范围内的聊天记录,并将其导出为 TXT 或 CSV 文件。
- 步骤一:加载配置 使用内置的
os和json模块,加载wx_login/WX_OFFS.json文件,WX_OFFS.json文件存储了不同微信版本在内存中的“偏移量”。这些数据至关重要,因为它告诉后续的内存读取模块(wx_info_handler)应该去内存的哪个位置寻找密钥、微信ID等信息 - 步骤二:获取微信登录信息 从内存中读取当前登录的微信用户的信息,将上一步加载的
wx_offs(偏移量数据)和微信文件路径args.wechat_path传递给safe_get_wx_info;get_wx_info利用这些信息,调用更底层的内存搜索功能(在wx_login/core_utils/memory_search.py中实现)来扫描正在运行的WeChat.exe进程;它根据偏移量定位并提取出数据库的加密密钥(key)和用户的文件目录(wx_dir);最终返回一个包含用户信息的列表。其中,safe_get_wx_info增加了重试逻辑,确保在微信刚启动等不稳定情况下也能成功获取信息。 - 步骤三: 解密与合并数据库 使用上一步获取的密钥解密微信的数据库文件,调用
decrypt_database(key, micro_db, dec_micro)解密MicroMsg.db;循环遍历Msg/Multi/目录下的MSG*.db文件,并逐个调用decrypt_database批量解密MSG.db;调用merge_msg_databases(dec_list, merged)合并消息库 - 步骤四:获取群聊列表 从已解密的数据库中查询所有群聊的信息,接收解密后的
MicroMsg.db路径 (dec_micro) 作为参数,连接到这个数据库,并执行 SQL 查询,筛选出所有聊天室(通常以 @chatroom 结尾的 UserName),返回一个包含 (群聊ID, 群聊名称) 的元组列表 - 步骤五:查询指定聊天记录 根据用户选择的群聊和时间范围,从合并后的消息库中提取消息;接收合并后的消息库路径
merged、用户选择的群聊IDselected[0]、以及开始和结束的时间戳;连接到 merged 数据库,执行一个带WHERE条件的 SQL 查询,筛选出特定TalkerId(即群聊ID)在指定时间范围内的所有消息;返回一个消息列表,列表中的每个元素是一个字典,代表一条消息 - 步骤六:数据处理与导出 主函数通过调用本地定义的
get_contact_nickname函数,再次查询解密后的MicroMsg.db,将消息中的wxid(发言人ID)替换为其对应的昵称,丰富了输出内容;调用export_to_txt()或export_to_csv(),接收处理好的消息列表msgs和输出文件路径out_path,然后将数据格式化并写入最终的文件
| 函数名 | 功能描述 |
|---|---|
get_contact_nickname | 数据库查询工具:连接到已解密的联系人数据库 (MicroMsg.db),根据传入的 wxid(微信ID)查询并返回对应的用户昵称。如果找不到,则直接返回原始 wxid。 |
safe_get_wx_info | 稳定的信息获取器:作为 get_wx_info 的一个包装函数,增加了重试机制。当一次尝试未能从内存中获取到有效的微信登录信息(特别是密钥)时,它会短暂等待后自动重试,提高了在复杂环境下(如微信刚启动)的成功率。 |
run_main | 主流程执行函数:这是程序的核心,负责按顺序执行所有步骤: 1. 加载配置:读取 WX_OFFS.json 偏移量文件。2. 解析参数:使用 argparse 处理用户从命令行传入的参数(如群聊编号、日期范围等)。3. 获取密钥:调用 safe_get_wx_info 从微信内存中获取数据库密钥和用户路径。4. 解密合并:调用 exporter 模块的 decrypt_database 和 merge_msg_databases 函数,处理联系人库和聊天记录库。5. 用户交互:调用 exporter.get_all_group_chats 获取并显示群聊列表,处理用户的选择和日期输入。6. 查询数据:调用 exporter.get_messages_for_chat 从合并后的数据库中筛选出指定聊天记录。7. 数据丰富:调用本地的 get_contact_nickname 为每条消息添加发送者昵称。8. 导出文件:根据用户指定的格式,调用 exporter 模块的 export_to_txt 或 export_to_csv 生成最终文件。9. 清理工作:删除解密过程中产生的临时文件。 |
其它关键函数解释
该部分主要解释三个关键的函数调用:wx_login/wx_info_handler.py、group_chat_getter/exporter.py、group_chat_getter/interactive_cli.py。
wx_login/wx_info_handler.py
文件核心功能: 该模块负责与正在运行的微信进程进行底层交互。它通过直接读取进程内存,获取解密数据库所需的关键信息,如版本号、密钥、用户ID和文件路径。
| 函数名 | 功能描述 |
|---|---|
get_key_by_offs | 根据基地址和偏移量,从微信进程内存中读取一个指针,然后通过该指针定位并读取32字节的数据库密钥,最后以十六进制字符串形式返回。 |
get_info_string | 从指定的进程内存地址读取一个字符串,并能正确处理字符串末尾的结束符。 |
get_info_name | 读取一个内存地址以获取一个指针,然后调用 get_info_string 从指针指向的地址读取(如昵称等)字符串。 |
get_info_wxid | 扫描 WeChatWin.dll 模块的内存,通过查找特定路径字符串 (\Msg\FTSContact) 来定位并提取用户的 wxid。 |
get_wx_dir_by_reg | 通过读取 Windows 注册表来获取 “WeChat Files” 的主目录路径。如果注册表读取失败,则使用默认的文档路径。 |
get_wx_dir | get_wx_dir_by_reg 的一个简单包装函数。 |
get_info_details | 核心协调函数。它整合了上述功能:获取微信进程信息(PID、版本),根据版本找到内存基地址和偏移量,然后调用 get_key_by_offs 获取密钥,并通过验证密钥有效性来匹配正确的 wxid 和用户文件夹,最后获取昵称、账号等详细信息。 |
get_wx_info | 对外主接口。它首先查找系统中所有正在运行的 WeChat.exe 进程,然后对每个进程调用 get_info_details,最终返回一个包含所有已登录用户详细信息的列表。 |
group_chat_getter/exporter.py
文件核心功能: 该模块封装了所有与数据库操作相关的功能,包括解密、合并、查询和导出。它是数据处理的核心。
| 函数名 | 功能描述 |
|---|---|
decrypt_database | 接收密钥和加密的数据库路径,调用底层的解密模块 (pywxd_decrypt_mod) 将其解密后存为新文件。它也能识别并直接复制本身未加密的数据库。 |
merge_msg_databases | 将多个分片的聊天记录数据库 (MSG*.db) 合并成一个单一的、完整的消息数据库 (merged_msg.db),以便于进行统一查询。 |
get_all_group_chats | 连接到解密后的 MicroMsg.db,通过 SQL 查询 ChatRoom 和 Contact 表,获取所有群聊的 ID 和对应的群聊名称列表。 |
get_messages_for_chat | 连接到合并后的消息数据库,根据指定的群聊ID和时间范围,执行 SQL 查询,提取出所有符合条件的聊天记录。 |
export_to_txt | 将查询到的消息列表格式化为人类可读的文本(TXT)文件,包含时间、发送者和消息内容。 |
export_to_csv | 将查询到的消息列表导出为结构化的 CSV 文件,每一行代表一条消息,包含时间戳、发送者、内容、消息类型等多个字段,便于后续进行数据分析。 |
group_chat_getter/interactive_cli.py
文件核心功能: 该模块提供了一个交互式的命令行界面(CLI)来引导用户完成整个导出流程。它调用 exporter 模块中的函数来执行实际操作。
| 函数名 | 功能描述 |
|---|---|
start_session | 交互流程主函数。它按顺序执行以下操作: 1. 初始化:接收密钥和微信目录,并创建用于存放解密文件的临时文件夹。 2. 解密:调用 exporter.decrypt_database 批量解密所有相关的数据库文件。3. 合并:调用 exporter.merge_msg_databases 合并消息库。4. 展示与选择:调用 exporter.get_all_group_chats 获取群聊列表并展示给用户,让用户通过输入编号进行选择。5. 查询:调用 exporter.get_messages_for_chat 获取选定群聊的所有消息。6. 导出:调用 exporter.export_to_txt 和 export_to_csv 将结果保存到文件。7. 清理:删除所有临时的解密文件,完成操作。 |
集市爬虫
其实本来集市爬虫是承接上一部分的,但是后续经过研究,发现微信小程序的连接具有自己的一套体系;因此后续利用抓包,通过一条全新路径进行消息爬取。
该部分的代码结构为:
1
2
3
4
5
6
7
8
9
10
11
12
- data
|- zanao_detailed_info
|- inschool_posts_and_comments.db
|- outschool_mx_tags_data.db
- zanao-climber
|- main.py //这里负责模拟翻页和提取帖子ID
|- worker.py //这里用于多线爬取具体的帖子内容
|- crawler.py //这里包含用于爬取帖子的函数
|- data_handler.py //这里用于原始信息数据库的创建
|- embedding_and_compare.py //这里用openAPI与Dify连接,基于Schema协议导入工作流
|- utils.py //这里包括一些工具函数
|- config.py //这里主要包含一些配置
主函数解释
文件核心功能: 主函数将爬虫任务划分成了两个独立的爬取链(Chain):Chain A 用于爬取普通帖子,Chain B 用于爬取更复杂的跨校区话题帖子。系统架构更清晰,并采用了更高效的进程间通信方式。
| 函数名 | 功能描述 |
|---|---|
dispatch_task | 标准任务分发器:一个标准化的辅助函数,用于将不同类型的任务(由 task_type 区分)打包成统一的 JSON 格式并推入 Redis 队列。 |
get_user_choice | 用户交互工具:功能与版本一相同。 |
wait_for_workers_to_finish | (重要升级)高效等待函数:使用 Redis 的 发布/订阅(Pub/Sub) 模式。它会订阅一个特定的完成频道 (REDIS_DONE_CHANNEL),安静地等待,直到 Worker 完成任务并通过该频道发布完成信号。这种方式效率更高,资源消耗更低。 |
| 爬取链 A (普通帖子) | |
fetch_and_dispatch_chain_a | 爬取链A的生产者:负责处理普通帖子的扫描、去重和分发。 |
run_posts_history_mode | 普通帖子-历史模式:调用 fetch_and_dispatch_chain_a 来执行历史普通帖子的分块爬取。 |
run_posts_incremental_mode | 普通帖子-增量模式:调用 fetch_and_dispatch_chain_a 来执行普通帖子的增量监控。 |
| 爬取链 B (跨校区话题) | |
fetch_and_dispatch_chain_b | 爬取链B的生产者:这是一个全新的、更复杂的任务生产逻辑。 1. 获取话题列表:首先调用 crawler.fetch_hot_tags 获取一个“热门话题”的列表。2. 遍历话题:对列表中的每一个话题进行迭代。 3. 扫描话题内帖子:在每个话题内部,再调用 crawler.fetch_tag_threadlist 进行翻页扫描,获取该话题下的帖子ID。4. 去重与分发:将所有话题中发现的新帖子ID进行汇总、去重,然后调用 dispatch_task 分发。 |
run_mx_history_mode | 跨校区帖子-历史模式:调用 fetch_and_dispatch_chain_b 来执行历史跨校区话题内帖子的爬取。 |
run_mx_incremental_mode | 跨校区帖子-增量模式:调用 fetch_and_dispatch_chain_b 来执行跨校区话题的增量监控。 |
| 程序主入口 | |
main | 程序主入口: 1. 多功能菜单:提供了一个包含四个选项的菜单,允许用户分别对两种类型的帖子(普通/跨校区)执行历史或增量模式。 2. 清晰的流程控制:在用户选择一个模式执行完毕后,会询问是否返回主菜单,提供了更好的用户体验。 3. 初始化与退出逻辑:负责初始化系统状态和确保向 Worker 发送正确的启动与停止信号。 |
工作函数解释
worker.py 在这个分布式爬虫系统中扮演了 消费者(Consumer)和执行者(Executor) 的角色。它的主要职责是从 Redis 任务队列中不断地取出由 main.py(生产者)分发的任务,然后执行具体的、耗时的网络请求和数据存储操作。它被设计为可以多线程并发工作,以极大地提高数据爬取的效率。
核心设计理念包括:
- 生产者-消费者模式:
main.py和worker.py通过Redis任务队列完美地实现了这一经典设计模式,实现了任务生产和任务执行的解耦 - 高并发:通过
ThreadPoolExecutor,Worker能够同时处理多个爬取任务,充分利用网络I/O,效率远高于单线程爬取(注意,过高并发和过低冷却时间会导致用户的User Token被暂时封禁) - 可扩展的任务链:通过
dispatch_task和process_master_task的设计,可以非常容易地增加新的爬取链条(例如 “Chain C“),只需添加一个新的处理函数并在调度器中注册即可,而无需改动主循环 异步通信:通过Redis的控制信号 (STOP/CONTINUE) 和Pub/Sub完成信号,实现了生产者和消费者之间高效的、非阻塞式的状态同步- 健壮性与容错:
_retry_task机制使得爬虫能够应对网络不稳定等临时性问题,不会轻易中断
| 函数名 | 功能描述 |
|---|---|
dispatch_task | 任务派发器 (内部使用):这个函数允许 Worker 在处理一个任务的过程中,产生新的子任务。例如,在获取了帖子列表后,为每个帖子分发一个获取详情的子任务。这是实现复杂爬取链(Chain B)的关键。 |
_retry_task | 健壮性保障 - 任务重试机制:当一个任务因网络波动、API限制等原因执行失败时,此函数会将其重新放回 Redis 队列的尾部 (rpush),并增加其重试计数。如果达到最大重试次数,则放弃该任务。这确保了临时性错误不会导致数据丢失。 |
_fetch_all_comments | 通用工具 - 自动翻页器:这是一个非常实用的辅助函数,封装了获取一个帖子所有评论的逻辑。它会自动处理翻页,直到没有更多评论为止,极大地简化了主处理函数中的代码。 |
| 爬取链 A (处理普通帖子) | |
process_chain_a | 处理链A的执行器:这是处理普通帖子任务的核心逻辑。 1. 获取详情:调用 crawler.fetch_post_details 获取帖子的详细内容。2. 保存详情:调用 data_handler.save_post_details 将帖子详情存入数据库。3. 获取评论:调用 _fetch_all_comments 获取该帖子的所有评论。4. 保存评论:调用 data_handler.save_post_comments 将评论存入数据库。 |
| 爬取链 B (处理跨校区话题) | |
process_chain_b_start | 处理链B的起点:(在最新的架构中,此步骤已移至生产者 main.py,但在早期设计中) 它负责获取热门话题列表,并为每个话题分发一个 process_chain_b_get_threads 子任务。 |
process_chain_b_get_threads | 处理链B的中间步骤:(同样,此步骤也已移至生产者) 它负责获取单个话题内的帖子列表,并为每个帖子分发一个 process_chain_b_final_details 子任务。 |
process_chain_b_final_details | 处理链B的终点:此函数执行与 process_chain_a 类似的操作,但针对的是跨校区(MX)帖子的数据接口。1. 获取详情:调用 crawler.fetch_mx_thread_info 获取帖子详情。2. 保存详情:调用 data_handler.save_mx_threads 保存。3. 获取评论:调用 _fetch_all_comments (使用 crawler.fetch_mx_comment_list 接口) 获取评论。4. 保存评论:调用 data_handler.save_mx_comments 保存。 |
| 主调度与控制 | |
process_master_task | 主任务调度器:这是 Worker 的任务分发中枢。当从 Redis 队列中取出一个任务时,它会解析任务中的 type 字段,然后像一个“总机”一样,将任务转交给对应的处理函数(如 process_chain_a)。 |
update_progress_bar | 可视化界面 - 进度条更新器:此函数在一个独立的后台线程中运行,负责: 1. 监控批次:从 Redis 读取由生产者设置的总任务数 (REDIS_BATCH_TOTAL_KEY),并重置进度条。2. 更新进度:根据已处理的任务数和队列中的剩余任务数,实时更新 tqdm 进度条。3. 发送完成信号:当检测到一批任务处理完成时,通过 Redis 的 Pub/Sub (publish) 向生产者发送完成信号,触发 main.py 中 wait_for_workers_to_finish 的结束。 |
main | 程序主入口: 1. 初始化:创建数据库表、连接 Redis、启动 update_progress_bar 进度条线程。2. 创建线程池:使用 ThreadPoolExecutor 创建一个包含多个“工人”线程的线程池,数量由 config.py 中的 CONCURRENT_WORKERS 决定。3. 主循环:在一个无限循环中,首先检查来自生产者的控制信号 ( REDIS_CONTROL_SIGNAL_KEY)。如果信号是 ‘STOP‘,则安全关闭线程池并退出。否则,它会使用 brpop 阻塞式地从 Redis 任务队列中等待并获取任务。4. 提交任务:一旦获取到任务,就将其提交给线程池 ( executor.submit),由线程池中的空闲线程调用 process_master_task 来执行。 |
其它函数解释
zanao_climber/data_handler.py
文件核心功能: 这是项目的数据持久化层,全权负责所有与 SQLite 数据库的交互。它将爬取到的原始数据结构化地存储起来,并为高并发读写进行了优化。该模块将数据清晰地分成了两个独立的数据库
| 函数名 | 功能描述 |
|---|---|
_get_db_connection | 底层数据库连接器:一个内部函数,负责建立到指定 SQLite 文件的连接。核心优化:它启用了 WAL (Write-Ahead Logging) 模式和 NORMAL 同步模式,这对于多线程写入(如 worker.py)至关重要,因为它允许读写操作同时进行而不会互相锁定,大大提高了并发性能。 |
get_posts_db_conn | 数据库1连接器:获取用于存储普通帖子数据的数据库连接。 |
get_mx_db_conn | 数据库2连接器:获取用于存储跨校区话题(MX)数据的数据库连接。 |
setup_posts_db | 数据库1初始化:创建存储普通帖子(posts)和其评论(comments)的表结构。它使用 CREATE TABLE IF NOT EXISTS 确保可以安全地重复运行。同时,它还创建了索引 (INDEX) 以加速查询,以及一个视图 (VIEW) 来方便地联表查询帖子标题和评论内容。 |
setup_mx_db | 数据库2初始化:创建存储跨校区话题(hot_tags)、话题内帖子(mx_threads)和其评论(mx_comments)的表结构,同样包含了索引和视图。 |
save_post_details | 普通帖子详情存储:将从 API 获取的单个帖子详情字典,格式化并存入 posts 表。使用 INSERT OR REPLACE 语句,这意味着如果帖子已存在,则会用新数据覆盖它(实现更新效果)。 |
_flatten_comments_recursive | 评论数据转换器:一个关键的辅助函数。由于 API 返回的评论是嵌套结构(楼中楼),此函数通过递归,将其“展平”成一个简单的列表,同时为每条评论添加层级(level)和回复对象(reply_to)信息,便于存储和分析。 |
save_post_comments | 普通帖子评论存储:接收一个帖子ID和原始的评论列表,调用 _flatten_comments_recursive 进行转换,然后使用 executemany 将所有评论批量存入 comments 表,效率远高于单条插入。 |
save_hot_tags | 热门话题存储:将热门话题列表批量存入 hot_tags 表。 |
save_mx_threads | 跨校区帖子存储:将单个话题下的帖子列表批量存入 mx_threads 表。 |
save_mx_comments | 跨校区评论存储:与 save_post_comments 功能相同,但针对的是跨校区帖子的评论,并存入 mx_comments 表。 |
setup_all_databases | 总初始化入口:一个顶层函数,用于在程序启动时调用所有 setup_*_db 函数,确保所有数据库和表都已准备就绪。 |
zanao_climber/crawler.py
文件核心功能: 这是爬虫的网络请求模块。它封装了所有对 Zanao API 的 HTTP POST 请求,包含了处理网络错误、请求重试、API限流等逻辑,为上层模块(main.py 和 worker.py)提供了干净、可靠的数据获取接口
| 函数名 | 功能描述 |
|---|---|
_make_request | 健壮的网络请求核心:一个内部函数,是所有 API 请求的基础。 1. 生成签名:调用 utils.get_headers 生成复杂的、动态变化的请求头。2. 自动重试:当请求失败时,它会自动进行多次重试。 3. 智能退避:重试时会采用指数退避策略(等待时间越来越长),避免因请求过快而被封禁。 4. 处理限流:能专门识别 429 Too Many Requests 状态码,并进行更长时间的休眠。 |
fetch_post_list | 获取普通帖子列表:调用 _make_request 请求帖子列表接口,并返回帖子ID和时间的列表。 |
fetch_post_details | 获取普通帖子详情:调用 _make_request 请求单个帖子的详细信息接口。 |
fetch_post_comments | 获取普通帖子评论:调用 _make_request 请求单个帖子的评论列表接口。 |
fetch_hot_tags | 获取热门话题列表:调用 _make_request 请求跨校区模块的热门话题列表接口。 |
fetch_tag_threadlist | 获取话题内帖子列表:调用 _make_request 请求指定话题下的帖子列表接口。 |
fetch_mx_thread_info | 获取跨校区帖子详情:调用 _make_request 请求单个跨校区帖子的详情接口。 |
fetch_mx_comment_list | 获取跨校区帖子评论:调用 _make_request 请求单个跨校区帖子的评论列表接口。 |
zanao_climber/utils.py 和 config.py
| 文件/函数名 | 功能描述 |
|---|---|
config.py | 中央配置文件:将所有可变参数集中存放。包括: 1. USER_TOKENS 和 SCHOOL_ALIAS:用户身份信息。2. API_SALT: 用于生成签名的一个密钥。3. *_DELAY, MAX_TASK_RETRIES, CONCURRENT_WORKERS: 控制爬虫行为(如速度、并发数)的参数。4. *_URL: 所有 API 的接口地址。5. REDIS_*, DB_*: Redis 和数据库的配置信息。 |
utils.py | 通用工具模块:存放小而独立的辅助函数。 |
get_nd, md5_hash | 简单的工具函数,分别用于生成随机数字字符串和计算 MD5 哈希值。 |
get_headers | 动态请求头生成器:至关重要的函数。它根据 Zanao App 的逆向工程结果,为每一次 API 请求动态生成一套复杂的、包含时间戳和签名 (Ah) 的 HTTP 请求头。这是模拟真实客户端行为、绕过服务器基础反爬机制的关键。 |
zanao_climber/embedding_and_compare.py
文件核心功能: 这是一个独立的下游应用,它与爬虫本身没有直接关系,而是利用爬虫产生的数据。它启动一个 Flask API 服务器,该服务器能对数据库中的帖子内容进行语义向量化,并提供一个基于余弦相似度的语义搜索接口。此文件还特别为 Dify 平台进行了适配,可以作为一个AI Agent的工具(Tool)
| 函数名 | 功能描述 |
|---|---|
load_and_vectorize_posts | 数据预处理与加载核心: 1. 动态建列:启动时检查数据库表,如果不存在 embedding 列,会自动创建。2. 增量向量化:智能地只查询 embedding 为空的帖子,调用本地 Ollama LLM 服务(如 granite-embedding)将其标题和内容转换为向量。3. 持久化存储:将生成的向量存回数据库的 embedding 列中。4. 加载至内存:将所有已向量化的帖子数据和向量加载到内存中,以实现快速搜索。 |
/(health_check) | 健康检查接口:一个简单的 API 端点,用于确认服务正在运行。 |
/search (semantic_search) | 语义搜索接口: 1. 接收一个文本查询。 2. 使用 Ollama 将查询文本也转换为向量。 3. 计算查询向量与内存中所有帖子向量的余弦相似度。 4. 返回与查询内容最相似的帖子列表。 |
/tools/* 和 /openapi.json | Dify平台适配层: 1. /tools/healthCheck 和 /tools/semanticSearch 是对主接口的简单封装,使其符合 Dify 工具的调用规范。2. /openapi.json 则根据 APISpec 的定义,动态生成一个 OpenAPI (Swagger) 格式的 JSON 文件。Dify 可以通过读取这个文件,自动理解并集成这个API服务作为它的一个可用工具。 |
集市数据分析与信息采集
该部分基于上一部分数据库中的原始数据,利用多种手段对数据进行分析,支持实时分析或批量分析不同方向的内容,并通过结构化文本和统计图的方式对分析结果进行多角度呈现,同时支持对感兴趣主题的资源搜集。
该部分的代码结构为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- zanao_analyzer
|- core
|- resources
|- taxonomy.json //话题分类参考
|- __init__.py
|- entity_extractor.py //实体提取
|- sentiment_analyzer.py //情感分析
|- similarity_engine.py //相似度计算
|- statistics_engine.py //统计分析
|- execution
|- run_batch_analytics.py //批量分析处理后数据
|- run_realtime_pipeline.py //实时处理原始数据
|- applications
|- chart_visualizer.py //可视化程序
|- report_generator.py //文字生成部分程序
|- generated_charts
|- XXX_XXX.html //得到的可视化统计图
|- data_cleanup.py //用于清空原始数据统计是否被分析的参数列
|- source_db_preparer.py //数据准备
|- database_setup.py //新数据库设置
|- api_server.py //Dify工具部分
|- config.py //配置
数据库建立部分的解释
zanao_analyzer/source_db_preparer.py
文件核心功能: 这是一个一次性的准备脚本,其唯一目的是改造原始数据源。它会遍历所有由爬虫生成的原始数据库(如 inschool_posts_and_comments.db),并为需要被分析的表(如 posts)添加一个名为 analysis_status 的新列。
| 函数名 | 功能描述 |
|---|---|
add_status_column_to_table | 核心操作函数: 1. 安全检查:首先检查数据库文件和目标表是否存在,如果不存在则安全跳过,避免程序出错。 2. 防止重复:通过 PRAGMA table_info 命令,它会检查目标表中是否已经存在 analysis_status 列。如果已存在,它会打印一条信息并跳过,确保此脚本可以被安全地多次运行而不会产生副作用。3. 添加列:如果列不存在,它会执行 ALTER TABLE ... ADD COLUMN ... SQL语句,为表添加一个整型(INTEGER)的 analysis_status 列,并将其默认值设为 0。 |
| if name == ‘main’: | 主执行逻辑: 1. 从 config.py 文件中读取所有配置好的原始数据库路径和表名。2. 循环遍历这些配置,对每一个需要分析的表调用 add_status_column_to_table 函数。 |
zanao_analyzer/database_setup.py
文件核心功能: 这是另一个一次性的设置脚本,但它不操作原始数据库,而是负责创建并初始化一个全新的、专门用于存放分析结果的数据库(默认为 analysis.db)。它定义了所有分析结果表的“蓝图”或“骨架”(Schema)
| 函数名 | 功能描述 |
|---|---|
main | 表结构定义与创建: 1. 连接数据库:连接到由 config.py 中指定的分析数据库路径。如果文件不存在,SQLite 会自动创建它。2. 创建核心表 (base_analysis):这是最重要的一张表,用于存放对每一条原始数据(帖子或评论)进行基础分析后的结果,如情感倾向、提取出的实体等。它通过 UNIQUE(source_db, content_type, source_id) 约束确保每条原始记录只被分析一次。3. 创建汇总表:创建一系列用于存储聚合分析结果的表,例如: - entity_frequencies: 存储所有帖子中高频出现的实体(如人物、地点)及其词频。- user_stats: 存储用户相关的统计数据(如发帖数)。- temporal_analysis: 存储按时间维度分析的结果(如每日热点)。- post_classifications / related_posts: 存储更高级的分析结果,如帖子分类和帖子间的相似度关系。4. 外键关联:通过 FOREIGN KEY,将高级分析结果表与 base_analysis 表关联起来,保证了数据的一致性和完整性。 |
if __name__ == '__main__': | 主执行逻辑:直接调用 main 函数来执行数据库的创建过程。 |
这个脚本实现了读写分离的设计思想。原始数据(读)和分析结果(写)被存放在不同的数据库中。这样做的好处是:
- 清晰:数据职责分明,原始数据不受污染
- 性能:为分析结果设计的表结构可以进行专门的优化,以加速后续的查询和可视化
- 安全:可以随时删除并重建分析数据库 (
analysis.db),而不会影响到花费大量时间爬取下来的原始数据
zanao_analyzer/data_cleanup.py
文件核心功能: 这是一个维护和重置脚本,用于将整个分析系统恢复到“出厂设置”,方便重新进行完整的分析。它执行与前两个脚本相反的操作
| 函数名 | 功能描述 |
|---|---|
clear_analysis_database | 清空分析结果: 1. 连接到 analysis.db。2. 遍历所有分析结果表。 3. 对每张表执行 DELETE FROM {table}; 命令,删除表中的所有数据,但保留表结构。4. 执行 DELETE FROM sqlite_sequence WHERE name='{table}';,重置自增主键(AUTOINCREMENT),使得下一次插入数据时ID从1开始。 |
| reset_source_databases | 重置原始数据状态: 1. 遍历所有原始数据库。 2. 对每个需要分析的表,执行 UPDATE {table_name} SET analysis_status = 0; 命令。3. 这会将所有帖子的状态标记重置为“未分析”,使得分析流水线可以从头开始处理所有数据。 |
if __name__ == '__main__': | 用户交互与执行: 1. 危险操作警告:首先向用户显示一个明确的警告,告知此操作会清除所有分析结果。 2. 获取确认:要求用户输入 y 来确认操作,防止误操作。3. 顺序执行:在用户确认后,依次调用 clear_analysis_database() 和 reset_source_databases(),完成整个清理和重置流程。 |
在数据分析和算法调试过程中,我们经常需要调整分析逻辑并重新运行整个流程。这个脚本提供了一个一键化的解决方案,避免了手动删除数据库文件或执行复杂的SQL命令,极大地提高了开发和实验的效率。它使得整个分析过程变得可重复和可预测。
核心组件部分的解释
实体提取器(EntityExtractor)
文件核心功能: 这个类封装了一个命名实体识别(NER)模型。它的职责是从一段文本中识别并提取出预先定义好的实体类别,如“人物”、“地点”、“组织”、“产品”等。通过提取文本中的关键实体,我们可以对非结构化的帖子内容进行结构化处理。
| 类/方法名 | 功能描述 |
|---|---|
EntityExtractor | 实体提取器类 |
__init__ | 模型初始化: 1. 设备选择:自动检测是否有可用的NVIDIA GPU (cuda),如果有则使用GPU进行计算,否则使用CPU,以最大化性能。 2. 加载模型:从 config.py 中获取预设的NER模型名称(例如 urchade/gliner_base),并使用 GLiNER.from_pretrained() 加载预训练模型。3. 加载标签:从 config.py 加载一个默认的实体标签列表 (NER_LABELS),这是模型在没有被指定特定标签时需要识别的实体类型。 |
extract | 核心提取方法: 1. 接收输入:接收需要分析的文本字符串。 2. 调用模型:使用加载好的 GLiNER模型 的 predict_entities 方法,一次性地在文本中寻找所有指定的实体标签。3. 返回结果:返回一个标准化的列表,其中每个元素是一个字典,包含了被识别出的实体文本、它的标签(类别)以及模型的置信度分数。 |
情感分析器(SentimentAnalyzer)
文件核心功能: 这个类封装了一个情感分类模型。它的职责是判断一段文本所表达的情感是积极的(positive)、消极的(negative)还是中性的。
| 类/方法名 | 功能描述 |
|---|---|
SentimentAnalyzer | 情感分析器类 |
__init__ | 模型初始化: 1. 设备选择:与 EntityExtractor 相同,自动选择 cuda 或 cpu。2. 加载模型:使用 transformers 库,从 config.py 获取模型名称(如 distilbert-base-uncased-finetuned-sst-2-english),并加载对应的分词器(Tokenizer)和分类模型。3. 动态索引:(核心健壮性设计) 它会自动读取模型配置文件中的标签映射( id2label),动态地找出“positive”和“negative”标签所对应的内部索引。这避免了因模型不同而导致硬编码索引出错的问题。 |
analyze | 核心分析方法: 1. 文本编码:使用分词器将输入文本转换为模型可以理解的数字ID。 2. 模型推理:将编码后的文本送入模型进行计算,得到一个输出( logits)。3. 计算概率:通过 softmax 函数将模型的原始输出转换为各类别的概率。4. 计算分数:用“积极”概率减去“消极”概率,得到一个从-1到+1的分数,直观地表示情感强度。 5. 返回结果:返回一个包含情感标签( positive/negative)和对应分数的字典。 |
相似度引擎(SimilarityEngine)
文件核心功能: 这个类封装了一个文本向量化模型(也叫嵌入模型,Embedding Model)。它的职责是将文本转换成高维空间中的数学向量,并通过计算向量间的余弦相似度来判断文本间的语义相似度。它还被用于实现一个智能分类系统。
| 类/方法名 | 功能描述 |
|---|---|
SimilarityEngine | 相似度引擎类 |
__init__ | 模型与数据初始化: 1. 加载模型:使用 sentence-transformers 库加载一个预训练的文本嵌入模型(如 paraphrase-multilingual-MiniLM-L12-v2)。2. 预加载分类体系:从 taxonomy.json 文件中读取一个预定义的、树状的分类体系。3. 预编码分类向量:在初始化时,它会一次性地将分类体系中所有的标签(如“二手交易”、“租房合租”)全部转换成向量并缓存在内存中,极大地加速了后续的匹配过程。 |
calculate_post_similarity | 文本间相似度计算:接收两个文本,分别将它们编码成向量,然后计算并返回它们之间的余弦相似度分数(0到1之间,越接近1越相似)。 |
match_query_to_classification | 查询与分类匹配:将一段用户查询文本编码成向量,然后与内存中所有预编码好的分类标签向量进行比较,找出与查询最相似的几个分类标签。这是实现语义搜索的第一步。 |
get_db_equivalent_classifications | 分类“翻译官”:这是一个巧妙的二次匹配功能。它先从数据库中加载所有实际出现过的分类标签,然后将上一步找到的理论分类与之进行相似度匹配。这能解决“我想找‘租房’,但数据库里只有‘房屋租赁’和‘求合租’”这类问题,提高了搜索的召回率。 |
统计引擎(StatisticsEngine)
文件核心功能: 这个类不包含任何AI模型,而是扮演一个数据分析师的角色。它使用强大的数据分析库 Pandas,对 analysis.db 中由前三个模块产生的基础分析结果进行二次的、复杂的聚合与统计计算。这个模块负责从海量数据中挖掘出有价值的、人类可理解的洞察(Insights)。它产生的结果可以直接用于生成数据报告、构建可视化仪表盘,或为决策提供数据支持。
| 类/方法名 | 功能描述 |
|---|---|
StatisticsEngine | 统计引擎类 |
__init__ | 初始化:接收一个到 analysis.db 的数据库连接,为后续操作做准备。 |
calculate_entity_frequencies | 计算实体词频:读取 base_analysis 表中所有的实体JSON数据,统计每种实体(如“考研”)在所有帖子中出现的总次数,并将结果存入 entity_frequencies 表。 |
analyze_user_relations | 分析用户关系:通过联结帖子表和评论表,分析用户间的互动行为。计算出谁是“超级连接者”(评论了最多不同作者的帖子)和“超级被连接者”(其帖子被最多不同用户评论),并将结果存入 user_stats 表。 |
track_hot_post_trends | 追踪热帖趋势: 1. 定义热度公式:创建一个综合性的“热度”分数,其权重由浏览量、评论数、点赞数和情感分数共同决定。 2. 计算热度:为近期(如7天内)的所有帖子计算热度分。 3. 排序与存储:找出热度最高的Top-K个帖子,并将这个排行榜作为 JSON存入 temporal_analysis 表。 |
detect_new_words | 发现新词/热词:通过比较近期(如7天)和历史时期(如30天)的实体词频,找出近期出现频率显著增长的词语,这些通常是新出现的热点或“梗”。结果同样存入 temporal_analysis 表。 |
执行部分的解释
实时分析流水线(execution/run_realtime_pipeline.py)
文件核心功能: 这个脚本扮演了实时数据处理器的角色。它被设计成一个可以持续运行的服务(守护进程),不断地监控原始数据库,一旦发现有新的、未被处理的数据,就立即对其进行基础的AI分析(情感和实体识别),并将结果存入分析数据库。
这个脚本实现了一个典型的 ETL(提取-转换-加载) 流水线:
- 提取 (
Extract): 从原始数据库SELECT新数据。 - 转换 (
Transform): 调用AI模型进行分析,将非结构化文本转换为结构化的情感和实体数据。 - 加载 (
Load): 将转换后的结果INSERT到分析数据库。
它通过 analysis_status 标志位实现了增量处理,确保了高效和不重复。这是一个需要长期在服务器后台运行的程序。
| 函数名 | 功能描述 |
|---|---|
process_data_source | 单一数据源处理器: 1. 连接与查询:以只读模式连接到指定的原始数据库(如 inschool_posts_and_comments.db),并查询出一批 analysis_status = 0 的新数据(帖子或评论)。2. 调用AI模型:对查询到的每一条数据,依次调用 SentimentAnalyzer 和 EntityExtractor 的分析方法,获取情感和实体结果。3. 存入分析库:将原始数据信息(如ID)和AI分析结果(情感、实体 JSON)打包,批量存入 analysis.db 的核心表 base_analysis 中。使用 INSERT OR IGNORE 防止因意外重复处理而导致程序崩溃。4. 更新状态:在数据成功存入分析库后,回写到原始数据库,将刚刚处理过的这批数据的 analysis_status 标记更新为 1。这一步是实现增量处理的关键闭环。5. 返回计数:返回本次处理的数据条数。 |
main_loop | 主循环与调度器: 1. 模型预加载:在循环开始前,一次性初始化 SentimentAnalyzer 和 EntityExtractor 对象。这避免了在每次循环中都重复加载耗时的AI模型,极大地提高了效率。2. 无限循环 ( while True):这是脚本持续运行的核心。3. 遍历数据源:在每次循环中,它会按顺序遍历所有定义好的数据源(如校内帖子、校内评论、校外帖子等),并调用 process_data_source 对它们进行处理。4. 智能休眠:如果在一轮完整的遍历后,没有发现任何新数据 ( total_processed == 0),程序会调用 time.sleep() 休眠一段时间(由config.py配置)。这避免了在空闲时持续占用CPU资源。5. 异常处理:使用 try...except 捕获循环中可能出现的任何错误,并在出错后短暂休眠后继续尝试,保证了服务的健壮性。 |
批量分析脚本(execution/run_batch_analytics.py)
文件核心功能: 这个脚本扮演了离线数据挖掘工的角色。它被设计成一个可以定期执行(例如,通过Linux的 cron 定时任务,每天凌晨运行一次)的批处理程序。它不处理实时新数据,而是基于 analysis.db 中已经积累的全量基础数据,进行计算成本高昂的、全局性的深度统计与聚合分析。
| 函数名 | 功能描述 |
|---|---|
run_statistics_module | 统计模块执行器: 1. 初始化引擎:创建一个 StatisticsEngine 的实例。2. 调用方法:依次调用 StatisticsEngine 中所有封装好的高级统计方法,如:1. calculate_entity_frequencies(): 计算全局实体词频。2. analyze_user_relations(): 分析全局用户关系网络。3. track_hot_post_trends(): 计算当天的热帖排行榜。4. detect_new_words(): 发现当天的新兴热词。 |
run_classification_module | 分类模块执行器: 1. 初始化引擎:创建一个 SimilarityEngine 的实例。2. 查找新帖子:通过 LEFT JOIN 查询,找出在 base_analysis 表中存在,但在 post_classifications 表中还没有对应记录的帖子。这实现了对新帖子的增量分类。3. 调用匹配:对每一个新帖子,提取其实体,并调用 SimilarityEngine 的 match_entities_to_classification 方法,将其与预定义的分类体系进行匹配。4. 存储结果:将所有成功的匹配结果(帖子ID、匹配到的分类、相似度分数)批量存入 post_classifications 表。 |
main | 主函数与流程编排: 1. 连接数据库:建立到 analysis.db 的连接。2. 顺序执行:按顺序调用 run_statistics_module() 和 run_classification_module(),完成所有批处理分析任务。 |
批注
- 实时流水线 (
run_realtime_pipeline.py) 只做轻量级的、可以快速完成的基础分析,确保新数据能被及时处理- 批量脚本 (
run_batch_analytics.py) 则负责处理那些需要扫描大量数据、计算复杂的聚合任务
将这两者分开,可以确保实时流水线的低延迟,同时也能在服务器负载较低的时段(如夜间)完成资源密集型的深度分析。这是一种非常经典和高效的大数据处理架构。
应用部分的解释
图表与词云生成器(applications/chart_visualizer.py)
文件核心功能: 这个模块扮演了数据可视化工程师的角色。它负责查询分析数据库或原始数据库,并使用强大的图表库 pyecharts 和 jieba(用于中文分词)来生成各种交互式的图表和词云,并将它们保存为HTML文件。这个模块将统计引擎计算出的复杂结果,以用户友好的方式呈现出来,使其价值能够被普通用户所理解和利用。
| 类/方法名 | 功能描述 |
|---|---|
ChartVisualizer | 图表可视化类 |
__init__ | 初始化:设置图表输出的目录路径。 |
_save_chart | 内部辅助 - 图表保存:一个统一的函数,负责将 pyecharts 生成的图表对象渲染成HTML文件,并保存到指定目录。文件名中包含时间戳,避免重名。 |
_get_all_text_from_source | 核心数据获取(新):这个方法直接连接到原始数据库(inschool_posts 等),而不是分析库。它会获取所有帖子和评论的原文,用于生成词云。这样做的好处是词云能反映最原始、最完整的文本信息。它还支持按 user_id 筛选。 |
create_word_cloud_chart | 生成词云图: 1. 调用 _get_all_text_from_source 获取所有文本。2. 使用 jieba 库对文本进行中文分词。3. 统计每个词语的出现频率。 4. 使用 pyecharts.WordCloud 将高频词语生成一张词云图,词语大小代表其频率。5. 可选地为特定用户生成个人词云。 |
create_sentiment_pie_chart | 生成情感分布饼图: 1. 连接到分析数据库 ( analysis.db)。2. 查询 base_analysis 表,统计所有“积极”和“消极”情感标签的数量。3. 使用 pyecharts.Pie 生成一张饼图,直观地展示社区整体的正面和负面情绪比例。 |
create_hot_trends_chart | 生成热帖排行榜条形图: 1. 连接到分析数据库。 2. 从 temporal_analysis 表中查询最新一天的“热帖趋势”数据(这是一个JSON字符串)。3. 解析 JSON,获取热帖的标题和热度分数。4. 使用 pyecharts.Bar 生成一个水平条形图,将热度最高的帖子按序排名,制作成排行榜。 |
create_sentiment_timeseries_chart | 生成情感时序趋势图: 1. 连接到分析数据库。 2. 查询 base_analysis 表中所有帖子的创建时间戳和情感标签。3. 使用 Pandas 库,按天对数据进行分组聚合,统计出每天产生的正面情绪帖子数和负面情绪帖子数。 4. 使用 pyecharts.Line 生成一张折线图,X轴是日期,Y轴是数量,清晰地展示社区整体情绪随时间变化的波动情况。 |
文本报告与预警生成器(applications/report_generator.py)
文件核心功能: 这个模块扮演了数据分析报告撰写者的角色。它不生成图片,而是查询分析数据库中的最终统计表,并将这些高度聚合的数据格式化成结构清晰、易于阅读的文本报告。
| 类/方法名 | 功能描述 |
|---|---|
ReportGenerator | 报告生成器类 |
__init__ | 初始化:接收一个到 analysis.db 的数据库连接,并设置 row_factory 以便按列名访问查询结果,增强代码可读性。 |
generate_user_profile | 生成用户画像报告: 1. 接收一个 user_id。2. 查询 user_stats 表,获取该用户的“超级连接者”等特殊统计标签。3. 查询 base_analysis 表,统计该用户所有发帖的情感分布(正面/负面占比)。4. 将这些信息整合成一段结构化文本,形成对单个用户的多维度分析画像。 |
get_latest_trends | 生成最新趋势报告: 1. 查询新词:从 temporal_analysis 表中获取最新的“新晋热词”排行榜JSON数据。2. 查询热帖:从 temporal_analysis 表中获取最新的“近期热帖”排行榜JSON数据。3. 格式化输出:将两个排行榜数据解析并格式化成易于阅读的列表,形成一份每日的“舆情摘要”或“趋势简报”。 |
其它部分的解释
中央配置文件(config.py)
文件核心功能: 这个文件是整个项目的 “控制总线”和“唯一真相来源”(Single Source of Truth)。它不包含任何执行逻辑,只负责定义和存储所有硬编码的字符串、路径、模型名称、API密钥、阈值等“魔法数字”。它的存在是为了让整个项目变得易于配置、维护和修改。
| 配置项类别 | 作用与目的 |
|---|---|
| 核心路径配置 | 包括(RAW_DB_PATHS, ANALYSIS_DB_PATH, RESOURCE_CLASSIFICATION_FILE_PATH, CHART_OUTPUT_DIR)。集中管理所有输入(数据库、资源文件)和输出(图表)的文件路径。当项目部署到不同环境时,只需修改这里即可,无需改动任何业务逻辑代码。 |
| 核心逻辑配置 | 包括(NER_LABELS, SOURCE_TABLES_CONFIG, BATCH_SIZE, SLEEP_INTERVAL)。定义了业务逻辑中的关键参数。例如,NER_LABELS 决定了实体提取器要识别哪些类型的实体;BATCH_SIZE 控制了实时流水线每次处理的数据量。 |
AI模型配置 (MODELS) | 这是一个模型注册表。它将不同功能(如情感分析、NER)与具体的Hugging Face模型名称解耦。如果未来想更换一个更好的情感分析模型,只需修改这里的字符串,而不需要去 SentimentAnalyzer 类中修改代码。 |
业务逻辑阈值 (THRESHOLDS) | 将算法和业务规则中的判断阈值集中管理。例如,negative_sentiment_alert 定义了多高的负面情绪分数会触发预警;entity_classification_match 定义了多高的相似度才算匹配成功。这些值可以根据实际效果方便地进行调整和优化。 |
| API服务配置 | 包括(API_PORT, PUBLIC_HOST)。定义API服务器运行的端口和对外暴露的公网IP/域名。 |
API 服务器(api_server.py)
文件核心功能: 这个文件是整个分析系统的 “对外服务窗口”。它使用高性能的Web框架 FastAPI,将 applications 和 core 层中已经开发好的各种功能(如图表生成、报告生成、智能搜索等)封装成一个个标准化的、符合 OpenAPI (Swagger) 规范的 RESTful API 端点。它的主要服务对象是像 Dify 这样的外部AI应用平台。
| 函数/代码块 | 功能描述 |
|---|---|
@asynccontextmanager lifespan | 生命周期管理(核心性能优化):这是FastAPI的一个高级功能。被这个装饰器包裹的代码会在服务器启动时执行一次,在服务器关闭时执行清理。这里用它来预加载 EntityExtractor 和 SimilarityEngine 这两个耗时的AI模型。这意味着模型只会被加载到内存中一次,而不是每次API请求时都重新加载,极大地提高了API的响应速度和吞吐量。 |
app = FastAPI(...) | 创建FastAPI应用实例:初始化FastAPI应用,并配置其标题、版本、OpenAPI文档路径等元数据。 |
app.add_middleware(CORSMiddleware, ...) | 配置CORS:添加跨域资源共享(CORS)中间件,允许来自任何源的请求访问此API。这是让Dify等Web应用能够顺利调用此API的必要设置。 |
app.mount("/charts", ...) | 挂载静态文件目录:将 generated_charts 目录作为一个静态文件服务器。这使得 ChartVisualizer 生成的HTML图表可以通过一个URL(如 http://.../charts/mychart.html)被直接访问。 |
get_db() | 数据库依赖注入:定义了一个FastAPI的依赖项。任何需要访问数据库的API端点,只需在函数参数中声明 db=Depends(get_db),FastAPI就会自动为该次请求建立并管理数据库连接,并在请求结束后自动关闭,保证了数据库连接的安全和高效管理。 |
class ... (BaseModel) | 定义Pydantic模型:使用Pydantic定义了API的请求体(Request Body)和响应体(Response Body)的数据结构。这样做的好处是:1. 自动数据校验: FastAPI会自动校验传入的JSON数据是否符合模型定义。2. 自动生成文档: FastAPI会根据这些模型自动生成详尽的、可交互的API文档。 |
@app.post(...) / @app.get(...) | 定义API端点 (Endpoint):每个这样的装饰器都定义了一个可被外部调用的API接口。 1. /tools/generate_chart:调用 ChartVisualizer 生成图表,并返回图表的URL。2. /tools/user_profile:调用 ReportGenerator 生成用户画像报告。3. /tools/discover/trends:调用 ReportGenerator 生成趋势报告。4. /tools/find/resources:这是最复杂的接口,它调用 SimilarityEngine 实现一个多阶段的智能资源发现(语义搜索)流程,最终从原始数据库中精确地找出并返回相关帖子的详细信息。 |
if __name__ == "__main__": | 启动服务器:使用 uvicorn 这个高性能的ASGI服务器来运行FastAPI应用。 |
项目实现
python编程环境的创建
这里推荐使用Anaconda prompt进行环境创建,命令如下:
1
2
3
4
conda create -n "Zanao-Climber" python==3.11
conda activate Zanao-Climber
python -m pip install --upgrade pip
pip install -r requirements.txt
如果环境配置出现问题,可能是因为有些包支持的安装方式不同;遇到这种问题时,可以自行搜索资料进行过解决。
微信群爬虫的实现
前置条件
首先,请确定你的微信版本号在WX_OFFS.json中存在;如下述json中”3.9.12.55”即为版本号
1
2
3
4
5
6
7
"3.9.12.55": [
94550988,
94552544,
94551016,
0,
94552480
]
运行步骤
使用管理员权限启动Anaconda Prompt,使用 cd 命令进入相应目录,然后激活您创建的Conda环境,然后执行主程序:
1
2
3
4
5
6
# 替换 "D:\path\to\your\project" 为您的实际项目路径
cd "D:\path\to\your\project"
# 激活环境
conda activate Zanao-Climber
# 执行主程序
python wx_login/main.py
交互指引
当您运行主程序后,它将引导您完成后续操作。通常会包括以下几个阶段:
- 自动获取微信信息:程序会首先尝试自动从内存中获取已登录微信的密钥等信息;如果成功,您会看到类似 “最终成功获取到 X 个有效微信用户的信息!” 的提示,并显示部分用户信息
- 选择群聊:程序会自动解密并读取您的群聊列表,然后将其展示在终端中,每个群聊前面都有一个编号;您需要根据提示,输入您想导出聊天记录的群聊所对应的编号,然后按回车
1 2 3 4
--- 可用群聊列表 --- [1] 技术交流与学习群 [2] 周末羽毛球小分队 [3] 公司项目A通知群
- 输入日期范围:接下来,程序会要求您指定需要导出的聊天记录的时间范围;请按照 YYYY-MM-DD 的格式依次输入开始日期和结束日期,每次输入后按回车
1 2
开始日期 YYYY-MM-DD: 2024-01-01 结束日期 YYYY-MM-DD: 2024-07-31
- 自动处理与导出:完成以上输入后,程序会自动查询、整理并导出数据;您会看到一系列处理进度的日志,如“正在查询聊天记录…”、“正在导出消息到…”;当看到“导出完成!”和“所有流程已完成”的提示后,表示任务已成功;导出的聊天记录文件(
.txt或.csv格式)会保存在项目根目录下的data/original_data/文件夹中 - 格式整理:在完成导出后,您可以运行文件夹
format_polisher下的integrated_cleaner.py程序进行格式修正
除了交互式操作,您也可以在运行命令时直接通过参数指定所有选项,以实现自动化,如:
1
2
# 导出第3个群聊,从2024-05-01到2024-05-31的记录,并保存为csv格式
python wx_login/main.py --chat-index 3 --start 2024-05-01 --end 2024-05-31 --format csv
- 可用参数说明:
--chat-index <编号>: 直接指定群聊编号。--start <日期>: 指定开始日期 (格式:YYYY-MM-DD)。--end <日期>: 指定结束日期 (格式:YYYY-MM-DD)。--format <格式>: 指定导出格式,可选值为txt或csv(默认为txt)。--wechat-path <路径>: 如果您的 “WeChat Files” 文件夹不在默认位置,可以使用此参数指定其完整路径。
集市爬虫的实现
前置条件
在实现本部分前需要配确认以下条件:
- Redis 服务:请确保您已在本地或服务器上安装并启动了
Redis服务,对于Windows用户,可以从Redis on Windows下载并安装;默认配置下,程序会连接到localhost的6379端口。如果您Redis的地址或端口不同,请修改zanao-climber/config.py文件中的REDIS_HOST和REDIS_PORT - 获取 User Token:您需要通过网络抓包工具(如
Fiddler,Charles,mitmproxy等)拦截微信小程序“在学校”的网络请求,从中找到X-Sc-Od请求头,其对应的值就是您的User Token;强烈建议使用多个不同的微信账号获取多个User Token,因为程序会随机选用,这可以有效分摊请求压力,降低单个账号被限制的风险 - 配置
config.py:打开zanao-climber/config.py文件,将您获取到的一个或多个User Token填入USER_TOKENS列表中;根据您的需求,可以调整CONCURRENT_WORKERS(并发线程数)和*_DELAY(请求延时)等参数,过高的并发和过低的延时会显著增加账号被临时封禁的风险
交互指引
本系统采用生产者 (main.py) 和消费者 (worker.py)分离的设计,它们是两个需要同时运行的独立进程。您需要至少打开两个终端来分别启动它们。
容器的创建、启动与停止
首先,您需要在Docker中启动Redis服务,具体方法为打开一个终端,运行以下命令来拉取最新的Redis镜像并启动一个名为 zanao-redis 的容器,相关操作如下:
1
2
3
4
5
6
7
8
9
10
# 创建新容器,并设置为只要Docker打开就自动启动该容器
docker run -d --name zanao-redis -p 6379:6379 --restart always redis
# 检查该容器是否在运行,输出列表中包含 zanao-redis,且状态为 Up,则表示Redis服务成功启动
docker ps
# 在关闭该容器后重启该容器
docker start zanao-redis
# 停止该容器
docker stop zanao-redis
# 重启该容器
docker restart zanao-redis
命令分解说明:
docker run: 运行一个新容器。-d: 后台运行 (Detached mode),容器会在后台持续运行。--name zanao-redis: 为容器指定一个友好的名称,方便后续管理。-p 6379:6379: 端口映射。将您电脑(主机)的6379端口映射到容器内部的6379端口。这是让您的Python代码能连接到容器内Redis的关键。--restart always: 自动重启。设置容器总是在Docker服务启动或容器意外退出时自动重启,确保服务的持续可用性。redis: 要使用的Docker镜像名称。Docker会自动从Docker Hub上拉取官方的Redis镜像。
启动爬虫进程
现在,Redis服务已在后台运行,配置也已完成。您可以启动爬虫的两个核心进程了。您需要至少打开两个终端。
打开第一个终端 (保持第一个终端的消费者仍在运行),进入项目根目录并激活Conda环境,运行 main.py 脚本来启动生产者进程。
1
2
3
cd "D:\path\to\your\project"
conda activate Zanao-Climber
python zanao-climber/main.py
打开第二个终端,进入项目根目录,并激活您的Conda环境,运行 worker.py 脚本来启动消费者进程。
1
2
3
cd "D:\path\to\your\project"
conda activate Zanao-Climber
python zanao-climber/worker.py
在生产者终端选择任务后,您可以在两个终端分别观察到任务的分发进度和处理进度;在生产者终端 (main.py) 中,按 Ctrl+C 或根据提示输入 q 退出,生产者退出时会自动通知消费者停止工作,消费者终端 (worker.py) 会在处理完当前所有任务后自动、安全地退出。
集市数据分析与信息采集的实现
前置条件
在实现本部分前需要配确认以下条件:
- 硬件要求:本系统的AI模型(特别是NER和Embedding模型)计算量较大,强烈推荐在配备有 NVIDIA GPU 和足够显存的机器上运行,以获得理想的处理速度;如果只有CPU,程序仍可运行,但AI分析(尤其是实时流水线)的速度会非常缓慢
- 依赖服务:
Ollama服务,确保您本地的Ollama服务正在后台运行。本系统通过API调用Ollama来执行部分AI推理任务;确保“集市爬虫”已经运行过,并且在data/zanao_detailed_info/目录下已经生成了inschool_posts_and_comments.db和outschool_mx_tags_data.db这两个包含原始数据的数据库文件 - 模型文件:首次运行本模块的脚本时,程序会自动从Hugging Face等模型社区下载所需的AI模型到您的本地缓存中(通常在用户目录的
.cache/huggingface下)。这个过程可能需要较长时间并占用一定的磁盘空间,请确保网络连接通畅。
首次运行:初始化与数据库准备
在第一次运行本分析系统时,您必须打开一个终端,使用cd进入项目根目录,并激活您的Conda环境,初始化原数据库和创建新数据库,看到 All tables for analysis.db have been set up successfully... 则表示成功。
1
2
3
4
# 准备原始数据库,为原始数据库添加 analysis_status 字段,用于后续的增量分析
python zanao_analyzer/source_db_preparer.py
# 创建分析结果数据库,即 analysis.db 文件,并设置好所有用于存储分析结果的表结构
python zanao_analyzer/database_setup.py
核心功能运行
初始化完成后,您可以根据需要运行系统的核心功能。通常分为实时处理、批量处理和API服务三个部分,您可以根据需求选择启动;当有进程未退出时,你可以选择用Ctrl+C终止该程序,或者重新开一个终端进行其它部分的运行。
1
2
3
4
# 持续地将原始数据进行基础AI分析并存入分析库
python zanao_analyzer/execution/run_realtime_pipeline.py
# 全局统计和深度分析
python zanao_analyzer/execution/run_batch_analytics.py
如果您需要通过Dify平台或其他应用来调用本系统的分析能力,请启动API服务器。服务启动后,在您的浏览器中访问 http://127.0.0.1:5060/docs,您会看到一个可交互的 Swagger UI 界面,其中详细列出了所有可用的API端点、参数和响应格式。您可以直接在这个页面上对API进行测试。
1
2
# 启动API服务器
uvicorn zanao_analyzer.api_server:app --host 0.0.0.0 --port 5060
查看与结果分析
API服务提供了 /tools/generate_chart 端点,调用后生成的图表会保存在 zanao_analyzer/generated_charts/ 目录下,这些 .html 文件可以直接用浏览器打开查看。
如果您想清空所有分析结果,并从头开始重新分析,可以运行清理脚本,删除所有分析数据。程序会要求您输入 y 进行二次确认。确认后,analysis.db 中的数据将被清空,同时原始数据库中的 analysis_status 标志位也会被重置为0。
1
python zanao_analyzer/data_cleanup.py
Dify工作流实现
Dify的准备与启动
你可以利用Git工具将Dify克隆到你的项目目录下,然后按照以下l流程创建Dify的相关容器:
-
在创建前请务必在
dify\docker\volumes\sandbox\dependencies\python-requirements.txt中加入:1 2 3
keybert sentence-transformers cachetools
-
同时修改
dify\docker\docker-compose.yaml:1 2 3 4 5 6 7
services: # ... 其他服务 ... sandbox: # ... 其他配置 ... volumes: # ... 其他挂载 ... - '/mnt/d/大学文件/大学学习/集市爬虫相关/-Zanao-information-extraction-classifier-/完整工程实现/data/zanao_detailed_info:/data:ro'
- 然后启动Dify
1 2 3 4
cd dify cd docker cp .env.example .env docker compose up -d
- 最后复制该网址,启动浏览器访问Dify界面:
http://localhost/install
Dify中模型的导入
首先下载ollama客户端,然后启动CMD或Windows PowerShell拉取模型,这里本人拉取的有两个模型,一个作为文本嵌入模型,一个作为语言模型:
1
2
ollama pull granite-embedding:278m
ollama pull gemma3
如果在后续运行过程中模型启动出现问题,你可以最小化于任务栏的ollama,转而在CMD或Windows PowerShell中启动:
1
ollama serve
然后点击右上角用户头像进入设置,点击左侧栏“工作空间”中的“模型供应商”,在“安装模型供应商”部分中找到ollama并安装,然后在上方的模型列表中从Ollma添加模型;模型名称填写你已经下载了的模型名称,基础URL填写Ollama Server的基础URL,其它部分按照模型特性填写即可。
Dify中自定义工具的导入
进入 ““工具” -> “创建自定义工具”,工具类型选择“基于OpenAPI规范导入”,在Schema地址中填入您 Zanao Analyzer API 服务的 openapi.json 地址(一般为http://<您的IP地址>:5060/openapi.json),然后按照步骤完成工具的设置,即可得到可以在工作流中插入的工具。
Dify中工作流的创建
进入 “工作室” -> “全部” -> “创建空白应用”,选择Chatflow创建支持记忆的复杂多轮对话工作流,然后利用自定义工具和ollma上拉取到的模型,基于Dify提供的节点模块进行个性化的工作流设计,从而实现集市信息的提取、分类、舆情分析和资料抽取。
结果呈现
工作流结果呈现
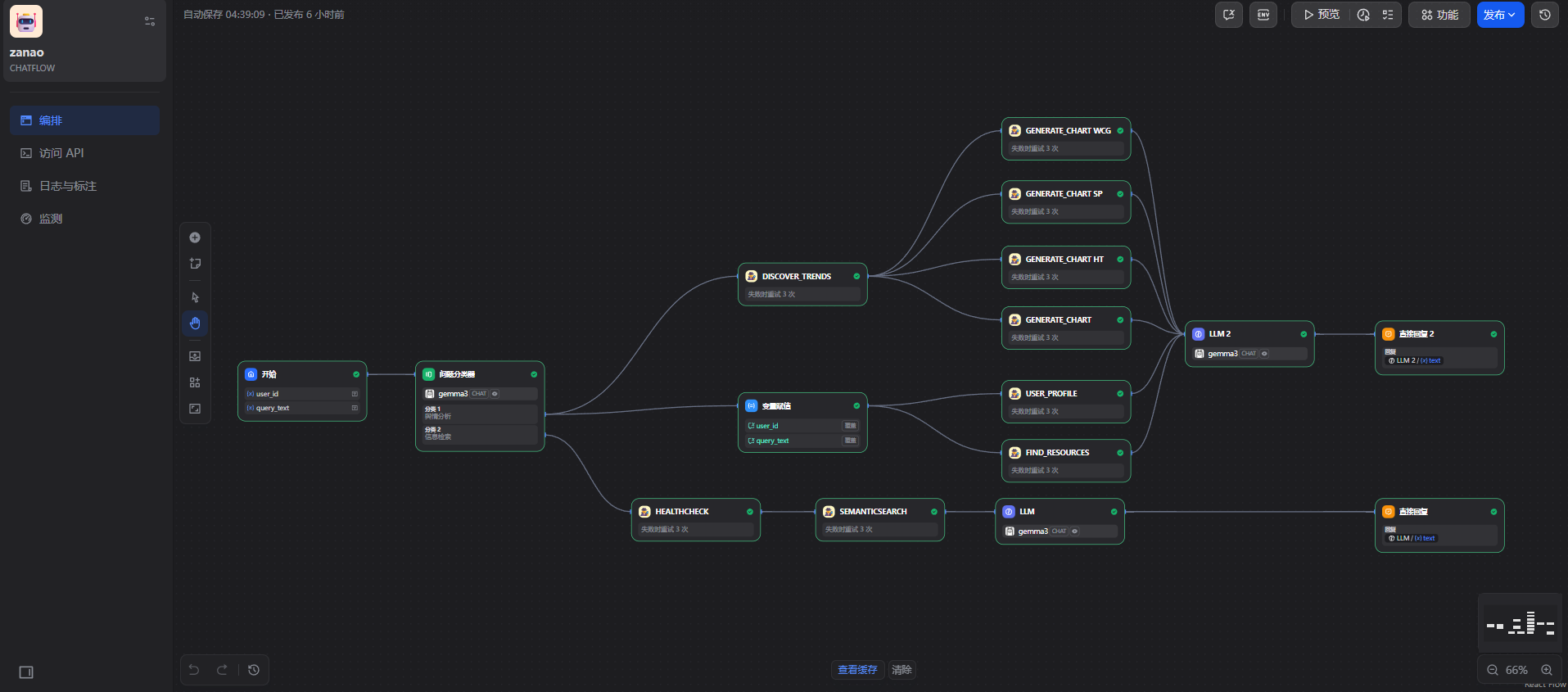
本人将工作流设计为两条,一条负责进行舆情分析,另一条负责具体信息查询与引用,整体工作流设计如下图。
交互实现
分支一:信息检索
案例输出结果如下图:
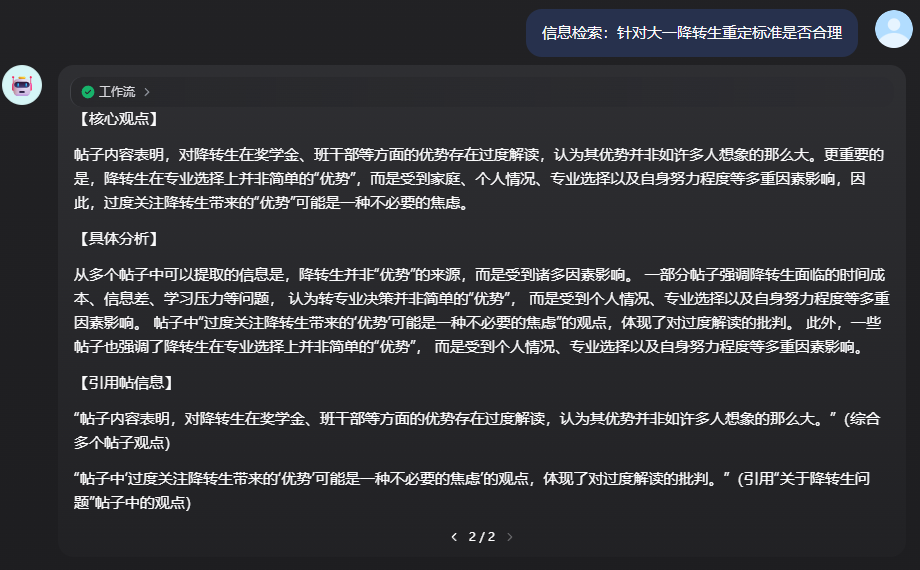
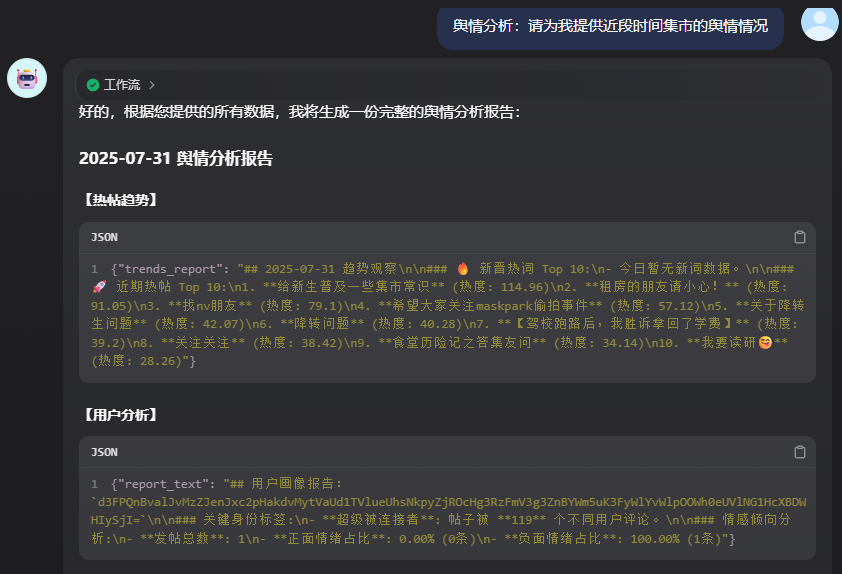
分支二:舆情分析
案例输出结果部分如下:
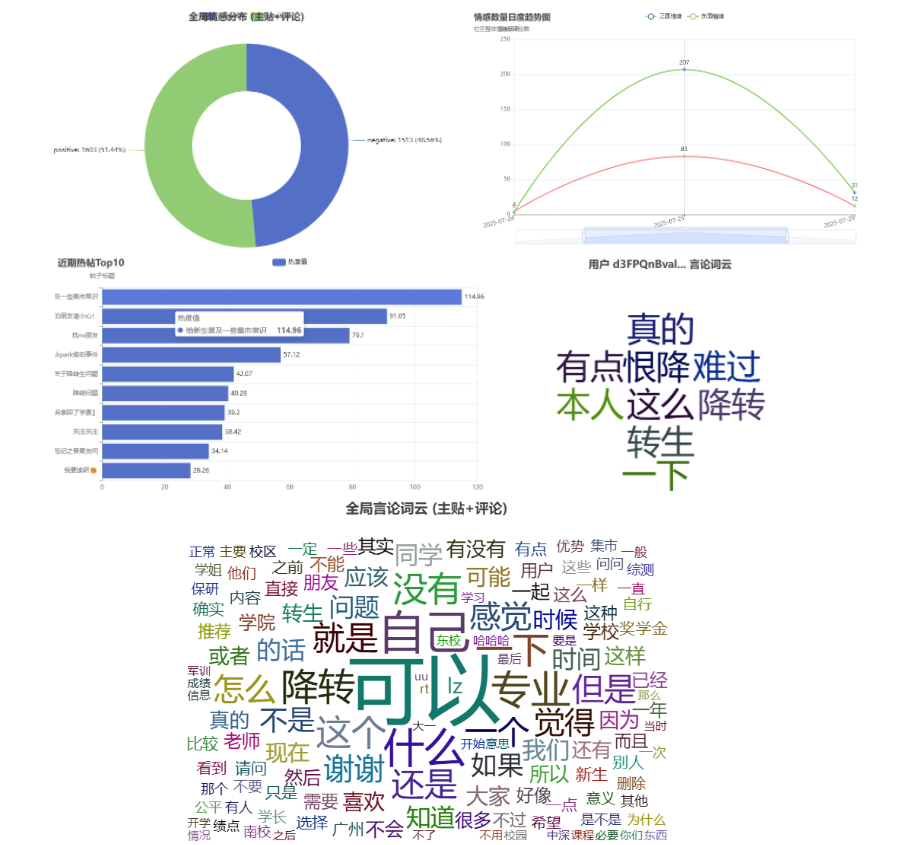
统计图呈现
得到的统计图包括:热帖分析条形图、情绪分布饼图、情绪时序图、全局词云图和用户词云图。为节省空间,现组合呈现如下:
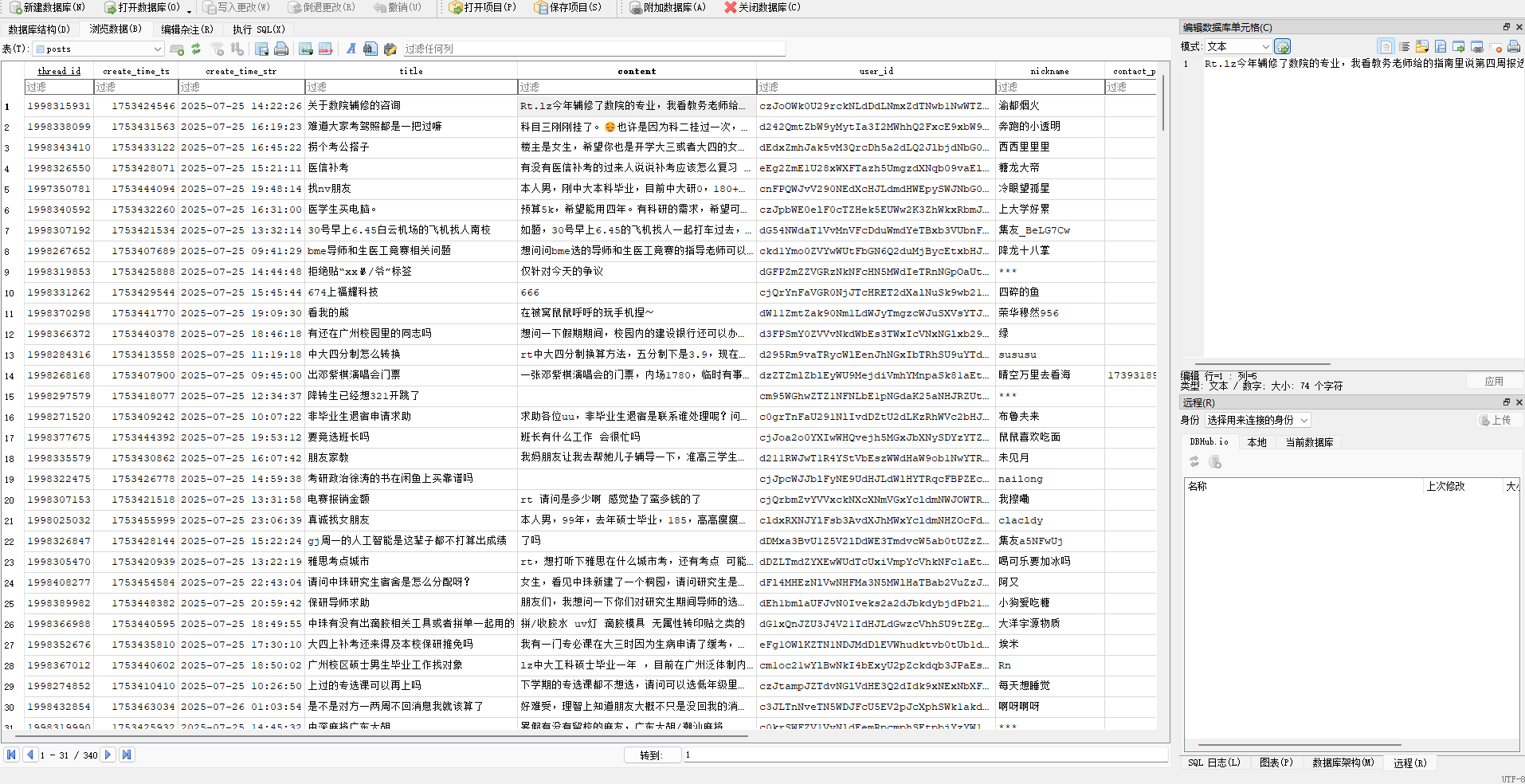
数据库呈现
得到的数据库包括:inschool_posts_and_comments.db、outschool_mx_tags_data.db、analysis.db。现以inschool_posts_and_comments.db中的帖子部分为例,部分呈现如下:
后续更新方向
- 优化爬虫设计,提升爬虫的执行效率和稳定性,提高爬虫安全性和单次
User Token使用时间,提升爬虫程序的智能型和自主性 - 优化数据库设计,针对不同数据库的不同表目,进行整合和调整,提高信息密度和丰富度;同时增加多模态数据库,存储如图片等非文本信息
- 优化代码流程设计,提供更加高效稳定的并行化处理方案,优化文件结构,优化API接口设计,提高处理效率,提供稳定的多平台调用方式
- 着手UI设计,开始建立前端页面,设计更加现代、好用、一体化的UI界面,提供更好的交互体验
- 优化工作流设计,提升硬件水平,提高模型能力,采用更先进的文本处理方案,引入多模态数据,优化工作流节点和字段设计,提高单次对话的处理效率和多轮对话连贯性,加强用户体验
附录:编程环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
Name Version Build Channel
aiohappyeyeballs 2.6.1 pypi_0 pypi
aiohttp 3.12.15 pypi_0 pypi
aiosignal 1.4.0 pypi_0 pypi
alabaster 1.0.0 pypi_0 pypi
altgraph 0.17.4 pypi_0 pypi
amqp 5.3.1 pypi_0 pypi
annotated-types 0.7.0 pypi_0 pypi
anyio 4.9.0 pypi_0 pypi
apispec 6.8.2 pypi_0 pypi
apispec-webframeworks 1.2.0 pypi_0 pypi
astor 0.8.1 pypi_0 pypi
attrs 25.3.0 pypi_0 pypi
babel 2.17.0 pypi_0 pypi
bce-python-sdk 0.9.42 pypi_0 pypi
billiard 4.2.1 pypi_0 pypi
blackboxprotobuf 1.0.1 pypi_0 pypi
blinker 1.9.0 pypi_0 pypi
blis 1.2.1 pypi_0 pypi
bzip2 1.0.8 h2bbff1b_6
ca-certificates 2025.2.25 haa95532_0
cachetools 6.1.0 pypi_0 pypi
camel-tools 1.5.6 pypi_0 pypi
catalogue 2.0.10 pypi_0 pypi
celery 5.5.3 pypi_0 pypi
certifi 2025.7.14 pypi_0 pypi
cffi 1.17.1 pypi_0 pypi
charset-normalizer 3.4.2 pypi_0 pypi
click 8.2.1 pypi_0 pypi
click-didyoumean 0.3.1 pypi_0 pypi
click-plugins 1.1.1.2 pypi_0 pypi
click-repl 0.3.0 pypi_0 pypi
cloudpathlib 0.21.1 pypi_0 pypi
colorama 0.4.6 pypi_0 pypi
coloredlogs 15.0.1 pypi_0 pypi
colorlog 6.9.0 pypi_0 pypi
comtypes 1.4.11 pypi_0 pypi
confection 0.1.5 pypi_0 pypi
contourpy 1.3.3 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
cymem 2.0.11 pypi_0 pypi
datasets 4.0.0 pypi_0 pypi
dbutils 3.1.1 pypi_0 pypi
decorator 5.2.1 pypi_0 pypi
dill 0.3.4 pypi_0 pypi
dnspython 2.7.0 pypi_0 pypi
docopt 0.6.2 pypi_0 pypi
docutils 0.21.2 pypi_0 pypi
editdistance 0.8.1 pypi_0 pypi
email-validator 2.2.0 pypi_0 pypi
emoji 2.14.1 pypi_0 pypi
eventlet 0.40.2 pypi_0 pypi
expat 2.7.1 h8ddb27b_0
fastapi 0.116.1 pypi_0 pypi
fastapi-cli 0.0.8 pypi_0 pypi
fastapi-cloud-cli 0.1.5 pypi_0 pypi
filelock 3.18.0 pypi_0 pypi
flask 3.1.1 pypi_0 pypi
flask-babel 4.0.0 pypi_0 pypi
flask-cors 6.0.1 pypi_0 pypi
flatbuffers 25.2.10 pypi_0 pypi
fonttools 4.59.0 pypi_0 pypi
frozenlist 1.7.0 pypi_0 pypi
fsspec 2025.3.0 pypi_0 pypi
future 1.0.0 pypi_0 pypi
gliner 0.2.21 pypi_0 pypi
greenlet 3.2.3 pypi_0 pypi
h11 0.16.0 pypi_0 pypi
httpcore 1.0.9 pypi_0 pypi
httptools 0.6.4 pypi_0 pypi
httpx 0.28.1 pypi_0 pypi
huggingface-hub 0.34.3 pypi_0 pypi
humanfriendly 10.0 pypi_0 pypi
idna 3.10 pypi_0 pypi
imagesize 1.4.1 pypi_0 pypi
indic-nlp-library 0.92 pypi_0 pypi
itchat 1.2.32 pypi_0 pypi
itsdangerous 2.2.0 pypi_0 pypi
janome 0.5.0 pypi_0 pypi
jieba 0.42.1 pypi_0 pypi
jinja2 3.1.6 pypi_0 pypi
joblib 1.5.1 pypi_0 pypi
kiwisolver 1.4.8 pypi_0 pypi
kombu 5.5.4 pypi_0 pypi
langcodes 3.5.0 pypi_0 pypi
langdetect 1.0.9 pypi_0 pypi
language-data 1.3.0 pypi_0 pypi
libffi 3.4.4 hd77b12b_1
lxml 6.0.0 pypi_0 pypi
lz4 4.4.4 pypi_0 pypi
marisa-trie 1.2.1 pypi_0 pypi
markdown-it-py 3.0.0 pypi_0 pypi
markupsafe 3.0.2 pypi_0 pypi
marshmallow 4.0.0 pypi_0 pypi
matplotlib 3.10.3 pypi_0 pypi
mdurl 0.1.2 pypi_0 pypi
morfessor 2.0.6 pypi_0 pypi
mpmath 1.3.0 pypi_0 pypi
muddler 0.1.3 pypi_0 pypi
multidict 6.6.3 pypi_0 pypi
multiprocess 0.70.12.2 pypi_0 pypi
murmurhash 1.0.13 pypi_0 pypi
networkx 3.5 pypi_0 pypi
numpy 1.26.4 pypi_0 pypi
ollama 0.5.1 pypi_0 pypi
onnx 1.17.0 pypi_0 pypi
onnxruntime 1.22.1 pypi_0 pypi
openssl 3.0.17 h35632f6_0
opt-einsum 3.3.0 pypi_0 pypi
orjson 3.11.1 pypi_0 pypi
packaging 25.0 pypi_0 pypi
paddle2onnx 1.3.1 pypi_0 pypi
paddlefsl 1.1.0 pypi_0 pypi
paddlenlp 2.6.1 pypi_0 pypi
paddlepaddle 2.5.2 pypi_0 pypi
pandas 2.3.1 pypi_0 pypi
pefile 2023.2.7 pypi_0 pypi
pillow 11.3.0 pypi_0 pypi
pip 25.1.1 pypi_0 pypi
pip-system-certs 5.2 pypi_0 pypi
preshed 3.0.10 pypi_0 pypi
prettytable 3.16.0 pypi_0 pypi
prompt-toolkit 3.0.51 pypi_0 pypi
propcache 0.3.2 pypi_0 pypi
protobuf 3.20.2 pypi_0 pypi
psutil 7.0.0 pypi_0 pypi
pyahocorasick 2.2.0 pypi_0 pypi
pyarrow 21.0.0 pypi_0 pypi
pyaudio 0.2.14 pypi_0 pypi
pycharts 0.1.5 pypi_0 pypi
pycparser 2.22 pypi_0 pypi
pycryptodome 3.23.0 pypi_0 pypi
pycryptodomex 3.23.0 pypi_0 pypi
pydantic 2.11.7 pypi_0 pypi
pydantic-core 2.33.2 pypi_0 pypi
pydantic-extra-types 2.10.5 pypi_0 pypi
pydantic-settings 2.10.1 pypi_0 pypi
pyecharts 2.0.8 pypi_0 pypi
pygments 2.19.2 pypi_0 pypi
pyinstaller 6.14.2 pypi_0 pypi
pyinstaller-hooks-contrib 2025.7 pypi_0 pypi
pymem 1.14.0 pypi_0 pypi
pyparsing 3.2.3 pypi_0 pypi
pyperclip 1.9.0 pypi_0 pypi
pypiwin32 223 pypi_0 pypi
pypng 0.20220715.0 pypi_0 pypi
pyqrcode 1.2.1 pypi_0 pypi
pyreadline3 3.5.4 pypi_0 pypi
pyrsistent 0.20.0 pypi_0 pypi
pysilk 0.0.1 pypi_0 pypi
python 3.11.13 h981015d_0
python-dateutil 2.9.0.post0 pypi_0 pypi
python-dotenv 1.1.1 pypi_0 pypi
python-mecab-ko 1.3.7 pypi_0 pypi
python-mecab-ko-dic 2.1.1.post2 pypi_0 pypi
python-multipart 0.0.20 pypi_0 pypi
pytz 2025.2 pypi_0 pypi
pywin32 311 pypi_0 pypi
pywin32-ctypes 0.2.3 pypi_0 pypi
pywinauto 0.6.9 pypi_0 pypi
pywxdump 3.1.45 pypi_0 pypi
pyyaml 6.0.2 pypi_0 pypi
rarfile 4.2 pypi_0 pypi
redis 6.2.0 pypi_0 pypi
regex 2025.7.31 pypi_0 pypi
requests 2.32.4 pypi_0 pypi
rich 14.1.0 pypi_0 pypi
rich-toolkit 0.14.9 pypi_0 pypi
rignore 0.6.4 pypi_0 pypi
roman-numerals-py 3.1.0 pypi_0 pypi
safetensors 0.5.3 pypi_0 pypi
scikit-learn 1.7.1 pypi_0 pypi
scipy 1.16.1 pypi_0 pypi
sentence-transformers 5.0.0 pypi_0 pypi
sentencepiece 0.2.0 pypi_0 pypi
sentry-sdk 2.34.0 pypi_0 pypi
seqeval 1.2.2 pypi_0 pypi
setuptools 59.8.0 pypi_0 pypi
shellingham 1.5.4 pypi_0 pypi
silk-python 0.2.7 pypi_0 pypi
simplejson 3.20.1 pypi_0 pypi
six 1.17.0 pypi_0 pypi
smart-open 7.3.0.post1 pypi_0 pypi
sniffio 1.3.1 pypi_0 pypi
snowballstemmer 3.0.1 pypi_0 pypi
spacy 3.8.7 pypi_0 pypi
spacy-legacy 3.0.12 pypi_0 pypi
spacy-loggers 1.0.5 pypi_0 pypi
sphinx 8.2.3 pypi_0 pypi
sphinx-argparse 0.5.2 pypi_0 pypi
sphinx-rtd-theme 3.0.2 pypi_0 pypi
sphinxcontrib-applehelp 2.0.0 pypi_0 pypi
sphinxcontrib-devhelp 2.0.0 pypi_0 pypi
sphinxcontrib-htmlhelp 2.1.0 pypi_0 pypi
sphinxcontrib-jquery 4.1 pypi_0 pypi
sphinxcontrib-jsmath 1.0.1 pypi_0 pypi
sphinxcontrib-qthelp 2.0.0 pypi_0 pypi
sphinxcontrib-serializinghtml 2.0.0 pypi_0 pypi
sqlcipher3-wheels 0.5.5 pypi_0 pypi
sqlite 3.50.2 hda9a48d_1
srsly 2.5.1 pypi_0 pypi
starlette 0.47.2 pypi_0 pypi
sympy 1.14.0 pypi_0 pypi
tabulate 0.9.0 pypi_0 pypi
tenacity 9.1.2 pypi_0 pypi
thinc 8.3.4 pypi_0 pypi
threadpoolctl 3.6.0 pypi_0 pypi
tk 8.6.14 h5e9d12e_1
tokenizers 0.19.1 pypi_0 pypi
torch 2.7.1 pypi_0 pypi
tqdm 4.67.1 pypi_0 pypi
transformers 4.43.4 pypi_0 pypi
typer 0.16.0 pypi_0 pypi
typing-extensions 4.14.1 pypi_0 pypi
typing-inspection 0.4.1 pypi_0 pypi
tzdata 2025.2 pypi_0 pypi
ucrt 10.0.22621.0 haa95532_0
ujson 5.10.0 pypi_0 pypi
urllib3 2.5.0 pypi_0 pypi
uvicorn 0.35.0 pypi_0 pypi
vc 14.3 h2df5915_10
vc14_runtime 14.44.35208 h4927774_10
vine 5.1.0 pypi_0 pypi
visualdl 2.5.3 pypi_0 pypi
vs2015_runtime 14.44.35208 ha6b5a95_10
waitress 3.0.2 pypi_0 pypi
wasabi 1.1.3 pypi_0 pypi
watchfiles 1.1.0 pypi_0 pypi
wcwidth 0.2.13 pypi_0 pypi
weasel 0.4.1 pypi_0 pypi
websockets 15.0.1 pypi_0 pypi
werkzeug 3.1.3 pypi_0 pypi
wheel 0.45.1 py311haa95532_0
wordcloud 1.9.4 pypi_0 pypi
wrapt 1.17.2 pypi_0 pypi
wxauto 39.1.12 pypi_0 pypi
wxpy 0.3.9.8 pypi_0 pypi
xxhash 3.5.0 pypi_0 pypi
xz 5.6.4 h4754444_1
yarl 1.20.1 pypi_0 pypi
zlib 1.2.13 h8cc25b3_1